
今回は、SeleniumでWebページのファイルをダウンロードする方法をサンプルコード付きで解説します。
ファイルダウンロード手順
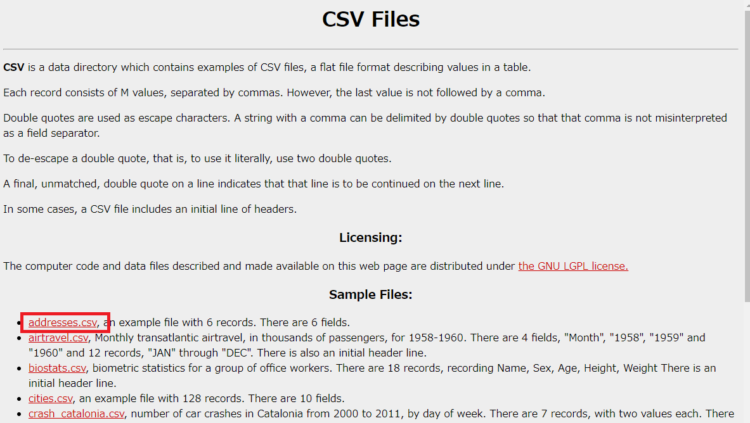
今回ダウンロードするファイル
ダウンロードするのは、フロリダ州立大学が提供しているサンプルCSVファイルとします。
ダウンロード対象の要素を取得
ダウンロードしたいファイルをクリックする処理をSeleniumで行うためには、ダウンロード対象の要素を特定する必要があります。
Webページ上で右クリック>検証、もしくはF12を押して開発者ツールを開きます。
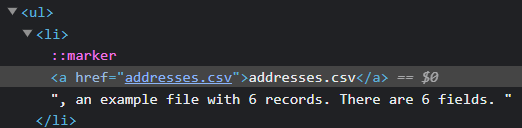
対象の箇所はリストは、ulタグ・liタグを使用したリストになっており、liタグはこのページ上に複数存在するためタグで取得するのは面倒そうです。そのため、XPathで取得します。
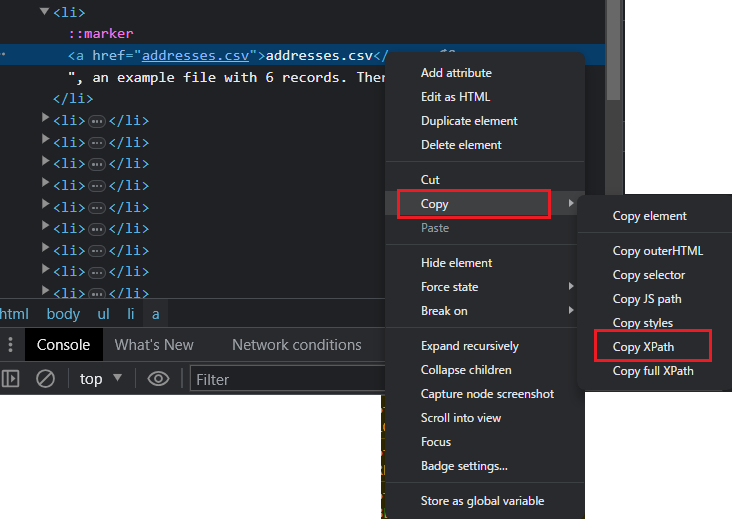
対象の箇所で右クリック>Copy>Copy XPath を選択します。
Seleniumのコード
取得したXPathを、以下コードに貼り付けます。
from selenium import webdriver
#import chromedriver_binary # chromedriver-binaryの場合これも必要
import time
from selenium.webdriver.common.by import By
# ブラウザの起動
driver = webdriver.Chrome()
driver.get('https://people.sc.fsu.edu/~jburkardt/data/csv/csv.html')
# ページが開くまで3秒待機
time.sleep(3)
# 要素を取得
element = driver.find_element(By.XPATH, '/html/body/ul/li[1]/a')
# 要素をクリック
element.click()
# ブラウザを閉じる
driver.close()ご自身の環境で試す際に変更する必要があるのは、青線を引いた2箇所です。
- driver.get(‘対象のページのURL’)
- element = driver.find_element(By.XPATH, ‘取得したい要素のXPath’)
コードの実行
実行すると、指定したCSVファイルがダウンロードされることが確認できました。
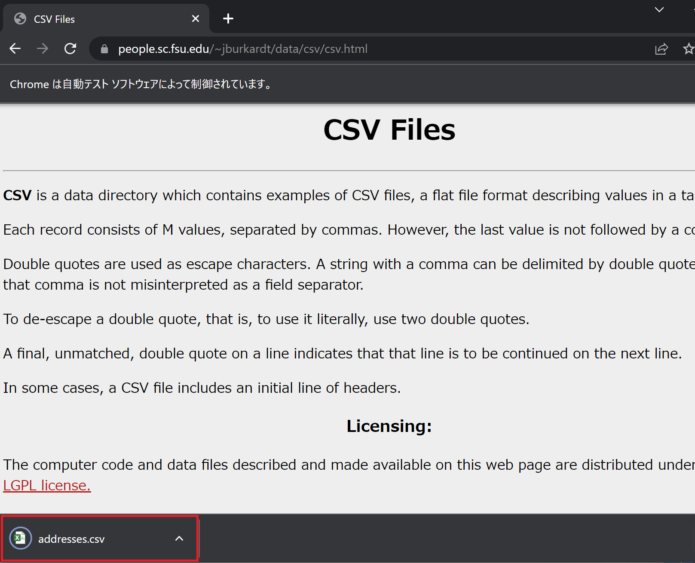
基本的なCSVダウンロード手順は以上です。
ダウンロード先を指定する場合
Webページのファイルをダウンロードする場合、デフォルトのダウンロード先は設定で指定されているダウンロード先です。(Chromeの場合「chrome://settings/downloads」を直接アドレスバーに入力すると確認できます)
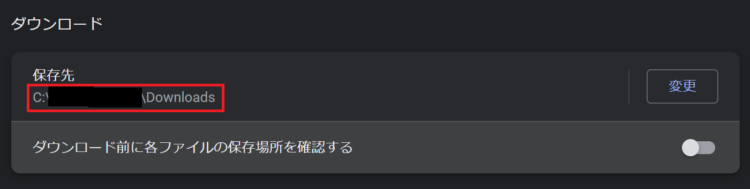
ダウンロード先を変更したい場合、上記の設定から変更することもできます。しかし、ブラウザ自体の設定が変更されてしまうので、Seleniumで実行するとき以外もダウンロード先が変更したものになってしまいます。
そこで、ソースコード内でダウンロード先を指定してあげます。
Seleniumでダウンロード先を指定する
Seleniumでダウンロード先を指定するには、webdriverのオプションにdownload.default_directoryを設定します。
{“download.default_directory”: [ダウンロード先の絶対パス] }
パスの指定方法は2通りあります。
パターン1:フルパスで指定
ダウンロード先をフルパスで指定する方法です。
from selenium import webdriver
#import chromedriver_binary # chromedriver-binaryの場合これも必要
import time
from selenium.webdriver.common.by import By
downloaddir = 'C:\\test\\downloads'
options = webdriver.ChromeOptions()
options.add_experimental_option("prefs", {"download.default_directory": downloaddir })
# ブラウザの起動
driver = webdriver.Chrome(chrome_options=options)
driver.get('https://people.sc.fsu.edu/~jburkardt/data/csv/csv.html')
# ページが開くまで3秒待機
time.sleep(3)
# 要素を取得
element = driver.find_element(By.XPATH, '/html/body/ul/li[1]/a')
# 要素をクリック
element.click()
# ブラウザを閉じる
driver.close()さきほどのソースコードとの変更箇所は、青色マーカーの部分です。ダウンロード先のフルパスを取得して、それをtestdir変数にセットします。このとき、そのままコピペするのではなく
C:\\test\\downloads
のように、「\」を2つ重ねて記載するようにします。
パターン2:カレントディレクトリに保存する
カレントディレクトリの取得は、以下メソッドで行います。
os.getcwd()
from selenium import webdriver
#import chromedriver_binary # chromedriver-binaryの場合これも必要
import time
from selenium.webdriver.common.by import By
import os
downloaddir = os.getcwd()
options = webdriver.ChromeOptions()
options.add_experimental_option("prefs", {"download.default_directory": downloaddir})
# ブラウザの起動
driver = webdriver.Chrome(chrome_options=options)
driver.get('https://people.sc.fsu.edu/~jburkardt/data/csv/csv.html')
# 以降はパターン1と同じこれで、カレントディレクトリ(現在プログラムを実行している場所)にダウンロードしたファイルが保存されます。もし、カレントディレクトリの下にダウンロード用のフォルダを作る場合は、
downloaddir = os.getcwd() + ‘\\downloads’
のように、フォルダ名を付加してあげることで指定できます。
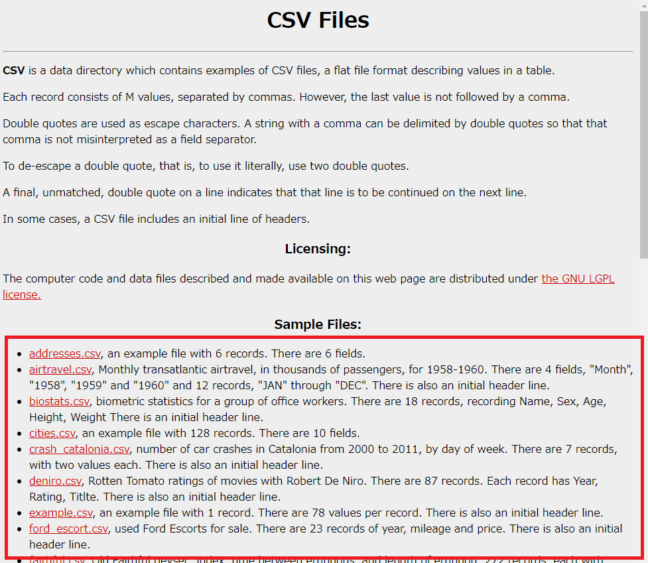
テーブル・リスト形式の場合
テーブルやリストになっている場合、親要素を取得してループを回すことで一気にダウンロードすることができます。
# ブラウザの起動
driver = webdriver.Chrome(chrome_options=options)
driver.get('https://people.sc.fsu.edu/~jburkardt/data/csv/csv.html')
# ページが開くまで3秒待機
time.sleep(3)
# リストタグの要素を全て取得
elements = driver.find_elements(By.TAG_NAME, 'a')
# ファイルのダウンロード
for i,el in enumerate(elements): # 最初の要素はとばす
if i > 0:
el.click()
time.sleep(5) # 連続してDLするので少し待機
全てのリンクタグ(aタグ)を取得して、XXX.csvを一つずつダウンロードします。最初のリンクはcsvファイルではないので、最初のループでは処理を飛ばします。
また、Seleniumは処理がとても速く、連続で大量のファイルをダウンロードすると負荷がかかってしまうのでsleepメソッドで待機しています。
インデックスを指定して取得することも可能
以下は、e-Statが提供している国勢調査データです。ここから、表番号1のExcelファイルのみダウンロードするとします。
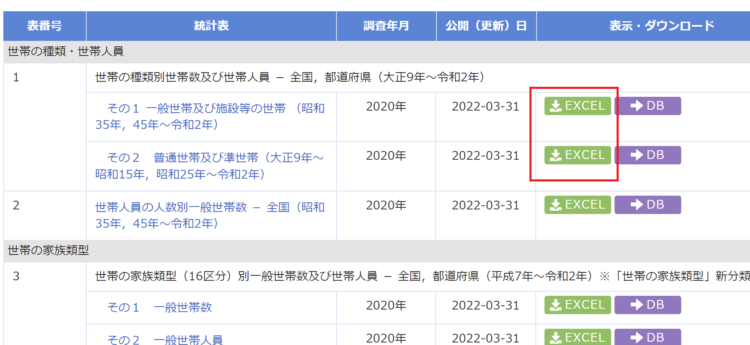
HTMLを見てみると、リンクタグ(aタグ)がExcelダウンロードボタン以外にも存在しているので、elem.get_attributeメソッドでうまく取得することができません。このような場合は、無理にリストで回すのではなく、XPathで直接指定するか、以下のようにリストのインデックスで指定するようにします。
# ブラウザの起動
driver = webdriver.Chrome(chrome_options=options)
driver.get('https://www.e-stat.go.jp/stat-search/files?page=1&layout=datalist&toukei=00200521&tstat=000001011777&cycle=0&tclass1=000001011805&result_page=1&tclass2val=0')
# ページが開くまで3秒待機
time.sleep(3)
# リストタグの要素を全て取得
elements = driver.find_elements(By.CLASS_NAME, 'stat-dataset_list-detail-item')
# 1番目のExcelファイルをダウンロード
el = elements[1].find_elements(By.TAG_NAME, 'a')
el[1].click()
time.sleep(5)
# 2番目のExcelファイルをダウンロード
el = elements[3].find_elements(By.TAG_NAME, 'a')
el[1].click()
うまくいかないとき
Seleniumでファイルダウンロードがうまくいかない場合の対処法です。
ヘッドレスモードだとうまくいかないことがある
Seleniumのファイルダウンロードは、ブラウザを表示せずにバックグラウンドで実行するHeadlessモードだと失敗することがあります。こちらのサイトにヘッドレスモードでファイルをダウンロードする方法が書いてありました。
指定した要素がクリックできない
以下のようなエラーが発生している場合は、指定した要素がリンクになっていなかったり、間違えて要素を指定していてクリックできていない可能性があります。
selenium.common.exceptions.ElementClickInterceptedExceptionselenium.common.exceptions.StaleElementReferenceException原因はいくつか考えられますが、
- 画面にクリックしたい要素が見えていない
- クリックしたい要素がまだ表示されていない
- 同じクラス名があって、別の要素が取得されてしまっている
等がよく起こりやすいです。要素の取得に失敗するときの対処法は以下記事でも紹介しています。

処理は正常に終了するがダウンロードされていない
処理は正常終了するけどファイルがダウンロードされない、ダウンロード先フォルダが開くだけでダウンロードに失敗するといった場合は、ファイルパス指定を間違えている可能性があります。
- C:\test\downloads # \でなく\\と書く
- C:/test//downloads # スラッシュでなくバックスラッシュを使う
まとめ
今回は、Seleniumでファイルをダウンロードする方法について解説しました。
定期的にダウンロードしたい、大量のファイルをダウンロードしたい等、手作業では大変な操作をSeleniumを使うと自動で行うことができます。
ファイルアップロード方法については以下記事にて解説しています。




コメント