
つい先日、「PADでGoogle検索結果一覧からURLを取得する方法」についてブログ記事を書きました。

この記事内では、「Webページからデータを抽出する」アクションを使って、CSSセレクタをURLが取れる形に加工するという方法を解説しました。ただ、この方法だと、様々なパターンに対応していないことが分かりました。
Googleの検索1位の構造は、いつも同じ構造になっているわけではなく、スポンサーやPRが入ったり、そもそもCSSセレクターの構造自体異なることもあるようです。
そこで、本記事にて、Google検索結果の一位を正確に取る方法について解説したいと思います。
概要
今回のフローは、
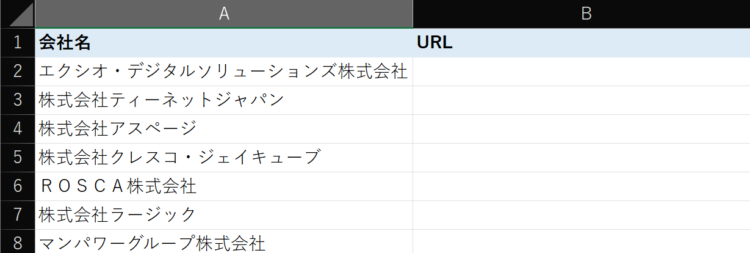
- Excelの会社名リストに入っている会社名でGoogle検索をする
- 検索結果の一位のURLを取得する
- Excelに結果を転記する
となります。Excelにはあらかじめ会社名がリストとして入力されている状態です。
※フロー全体については、本記事の最後に載せています。
Webページテキストを取得する
前回記事では「Webページからデータを抽出する」アクションを使いましたが、今回は以下のアクションを使います。
Webページ上の詳細を取得します
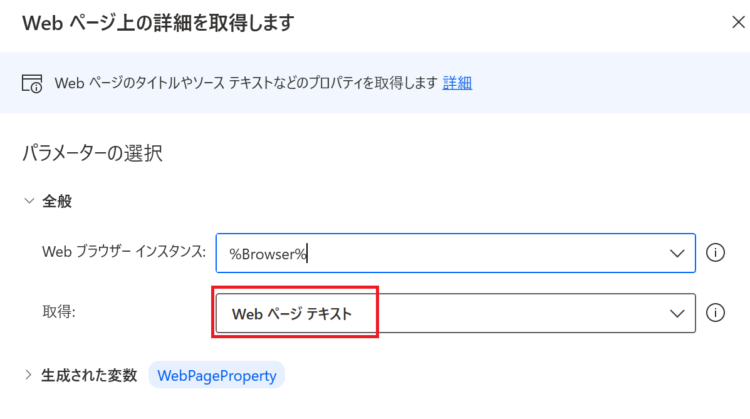
取得するのは「Webページテキスト」とします。これで実行すると、WebPageProperty変数の中には以下のような文字列が入ります。

取得したWebページテキストについて
テキストエディタにコピペして見てみると、画面上のテキストがそのまま入っています。
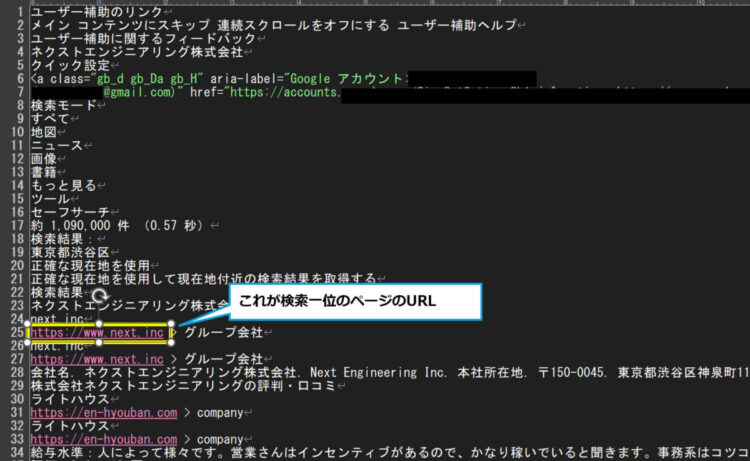
このなかから、一位のページのURLが取れれば良いので、「検索結果」という文字以降をいったんトリミングします。
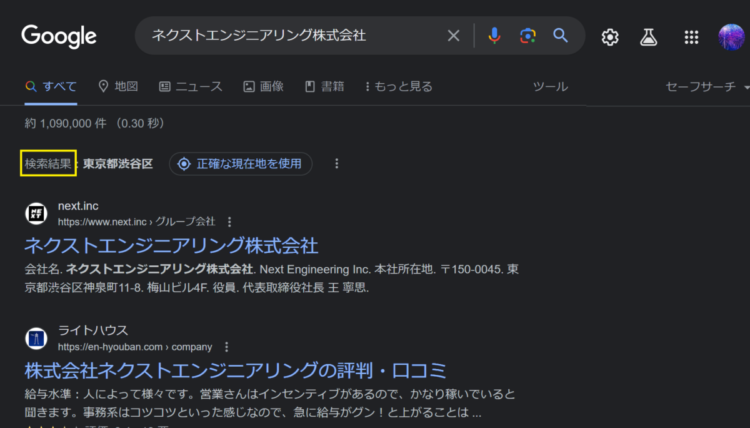
「スポンサー」を除外する
Googleの検索結果には、上部にスポンサーが入ることがあります。
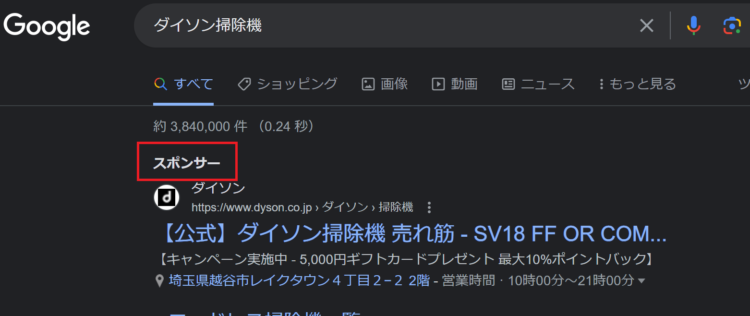
この場合、「Webページ上の詳細を取得します」アクションを実行すると、スポンサー部分も一緒に取れてしまいます。
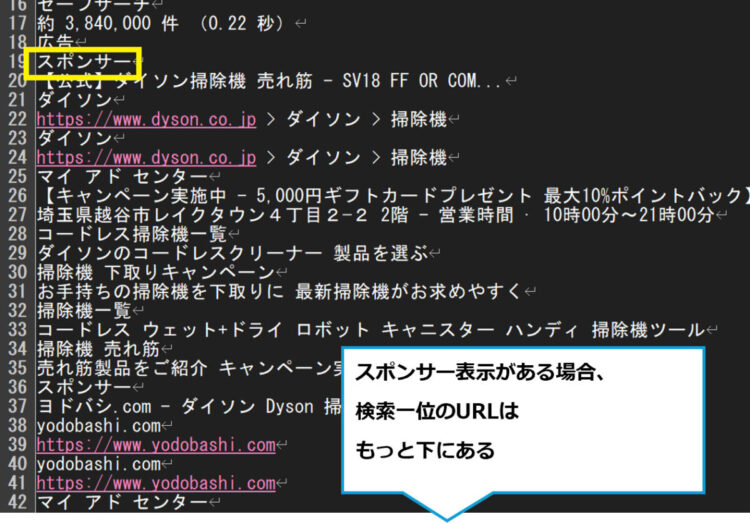
これを考慮した上で、取得したテキストの解析をしていきます。
テキストの解析
「Webページ上の詳細を取得します」アクションで取得したテキストの解析をします。
まず「スポンサー」を排除
スポンサーを排除します。
テキストの解析
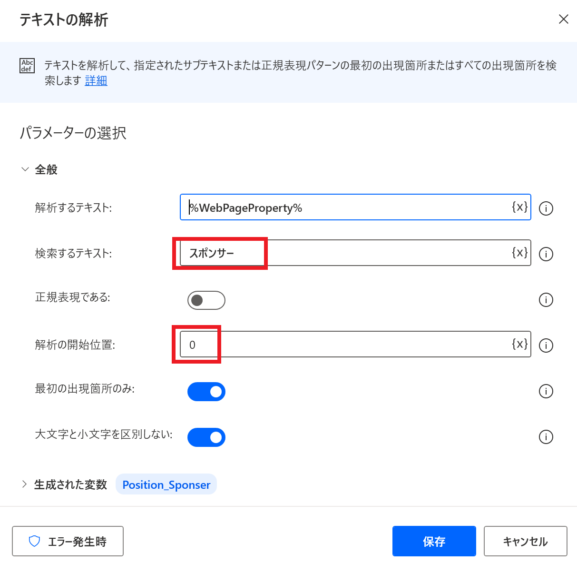
「検索するテキスト」には「スポンサー」を、解析の開始位置には0を指定します。「生成された変数」は、デフォルトではPositionとなっていますが、分かりやすくするために「Position_Sponser」と変更しています。
このアクションを実行すると、テキスト内に「スポンサー」という文字がある場合にPosition_Sponser変数には「スポンサー」という文字列が見つかった位置が格納されます。見つからない場合は-1が格納されます。
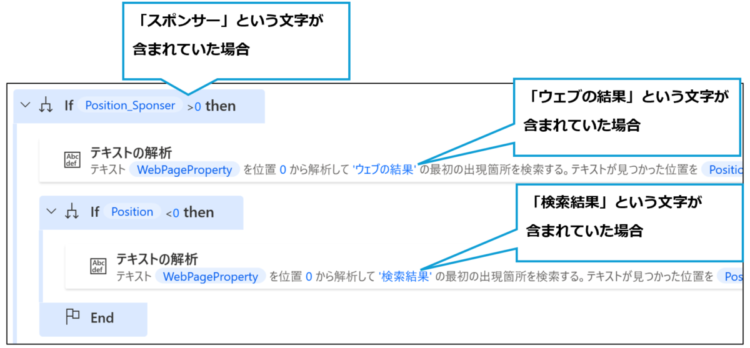
1つ目のIfでは、Position_Sponserが0より小さい場合、スポンサーが含まれているものとして処理します。ここで、検索文字は「ウェブの結果」とします。というのも、スポンサーが含まれている場合、「検索結果」ではなく「ウェブの結果」のあとに検索結果が表示される場合があるためです。
2つ目のIfでは、「ウェブの結果」が見つからなかったら、「検索結果」の位置を取得します。
文字列を抜き出す(サブテキストの取得)
検索一位のURLの位置が分かったら、今度はその位置を抜き出します。
サブテキストの取得
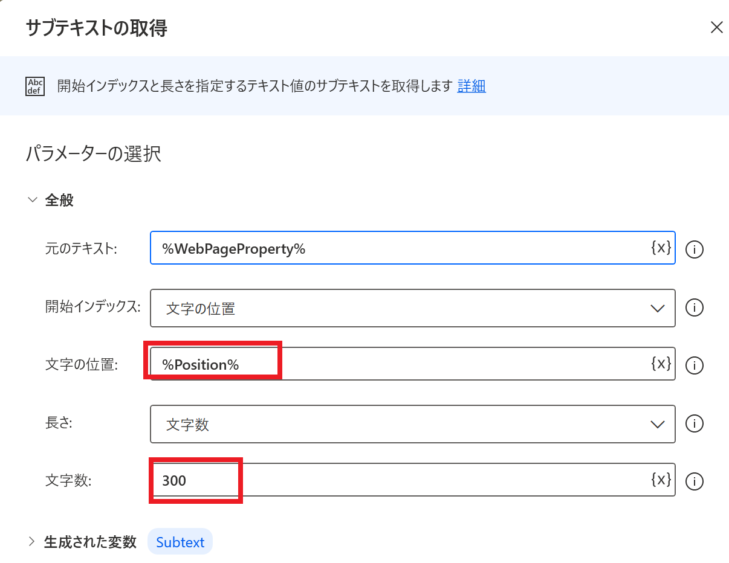
「テキストの解析」アクションで、「ウェブの結果」もしくは「検索結果」の位置がPosition変数に格納されています。そのため、「文字の位置」には%Position%を、そして抜き出す文字数は少し長めに300とします。
このアクションを実行すると、抜き出したテキスト(Subtext)には、検索一位のURLを含む文字列が取得されます。

URLを取り出す
検索一位のページのURL部分のみ取り出します。全体像は以下のようになります。
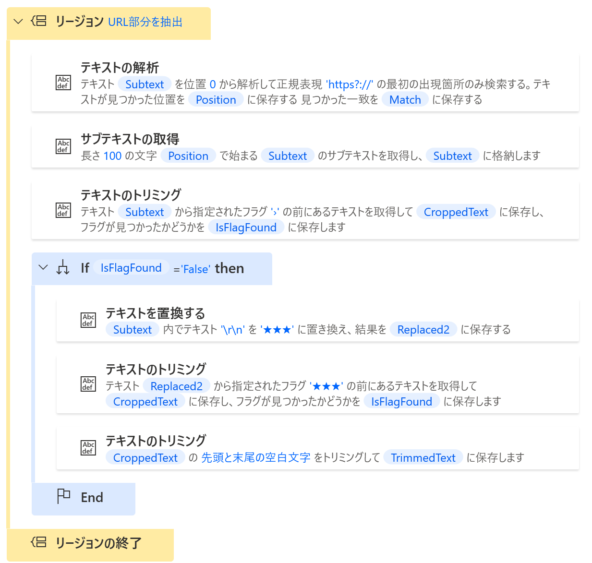
それぞれのアクションについて、以降で解説します。
テキストの解析
先ほど取得したSubtextから、httpまたはhttpsの文字列の開始位置を取得します。
テキストの解析
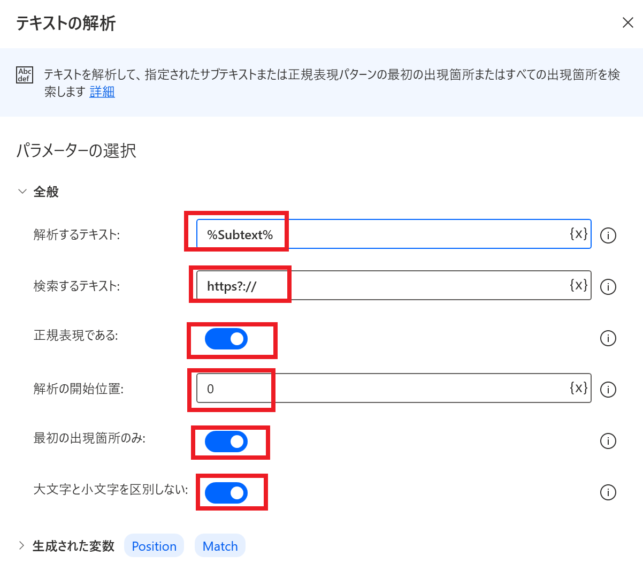
検索するテキストには「https?://」と入力し、その下の「正規表現である」にチェックを入れてください。
サブテキストの取得
サブテキストの取得
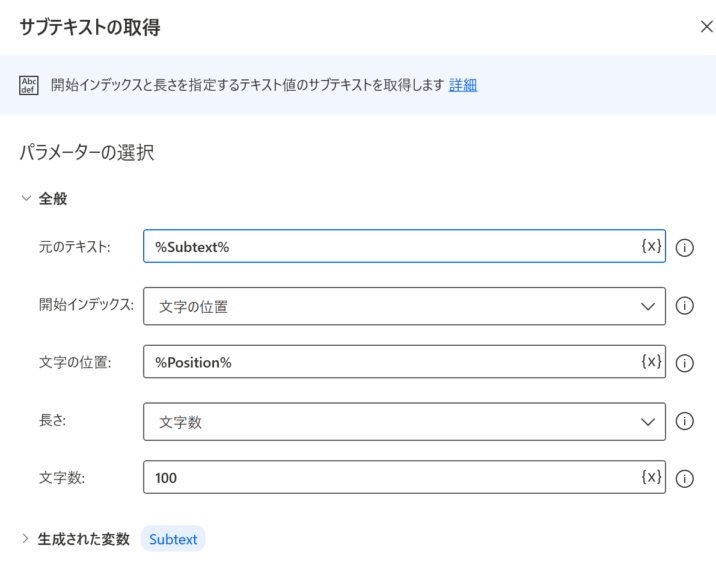
httpまたはhttpsが見つかった位置から100文字分切り出します。
余分な「›」以降の除去
取得したテキストの中身は、以下のようになっています。URLの後ろに、余計なものが含まれてしまっているので、これを除去した形で取得する必要があります。

テキストのトリミング
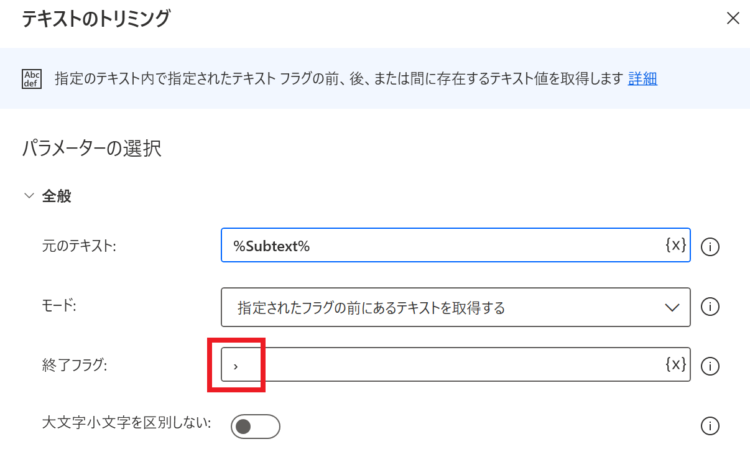
終了フラグには、
›を入力してください。「>」ではないので注意。このアクションにより、「https://www.biccamera.com › … › 家電・照明 › 加湿器」と余計な部分がついていたものが、URLのみになります。

「›」以降がないページの対応
URLに、「›」以降がないページもあります。
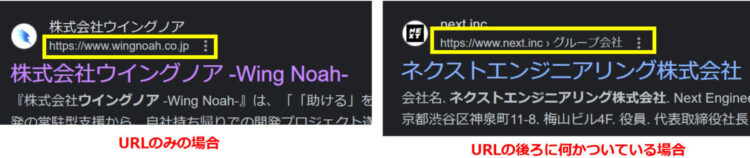
先ほどは「›」を目印にURLをトリミングしましたが、今回は改行コードを目印にトリミングします。
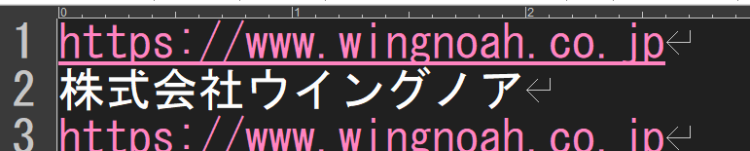
改行コード箇所を見つけて、「https://www.wingnoah.co.jp★★★」という文字列に置換します。そして、テキストのトリミングで「★★★」前までをトリミングすればURLのみ取得することができます。
テキストを置換する
テキストを置換する
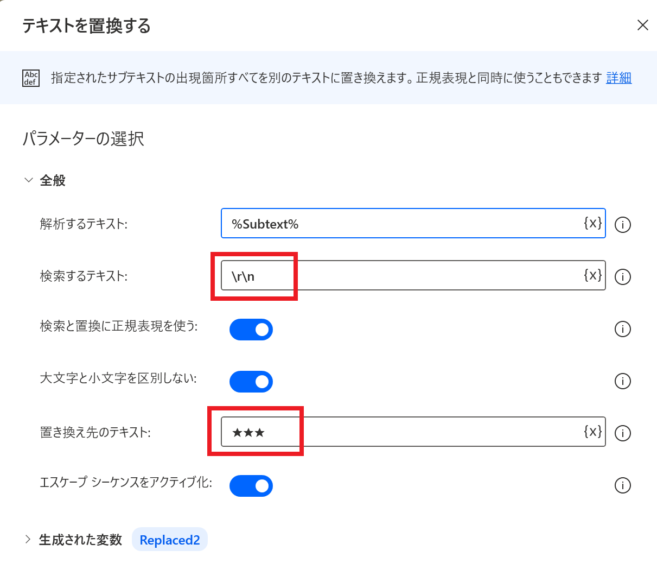
検索するテキストは
\r\n※PADに貼り付けると画像のように「\r\n」表記になります
置き換え先のテキストは「★★★」としていますが、「あああ」「***」など、テキスト内に存在しない文字であればなんでもOKです。
テキストのトリミング
テキストのトリミング
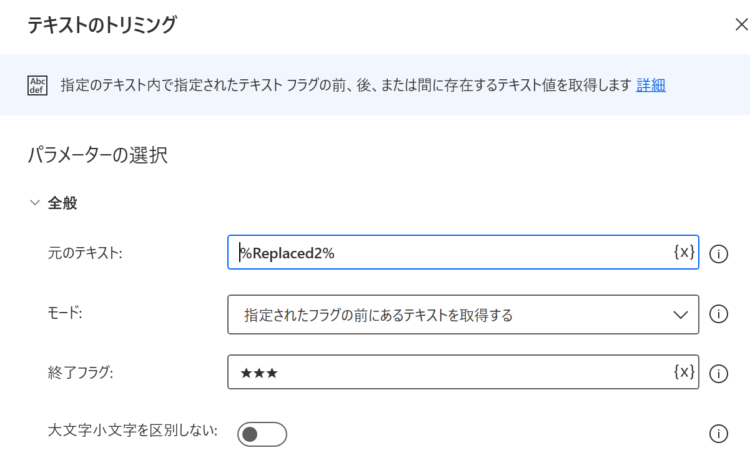
これで、URLのみ抜き出すことができました。

テキストのトリミング(空白の除去)
ここで使う「テキストのトリミング」アクションは、先ほどのものと違うので注意してください。

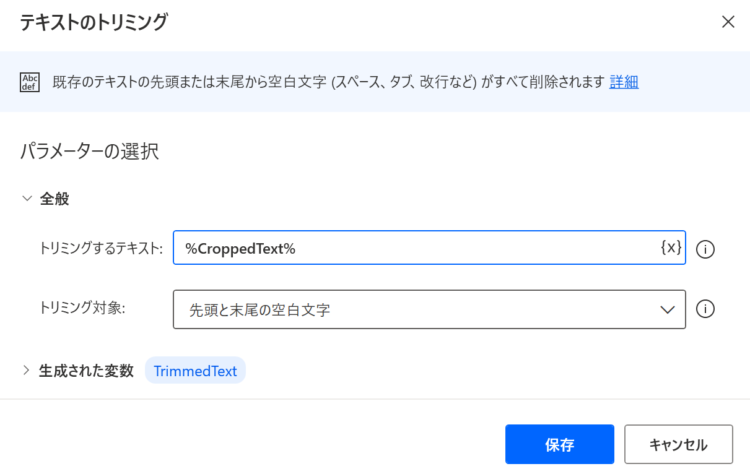
URLの、先頭・空白の余計な空文字などを除去しておきます。(このアクションを入れないと指定したURLにうまく遷移できないことがあったので追加しています)
URLをもとにWebページに移動
取得したURLをもとにWebページに移動します。
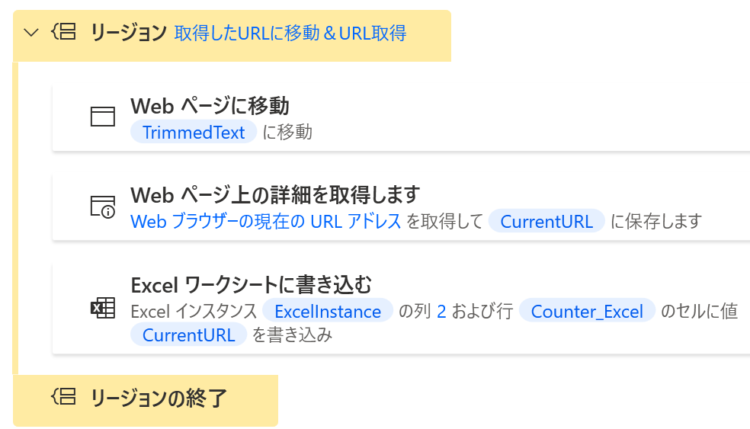
ここで、「Webページ上の詳細を取得します」アクションにて開いた先のURLを取得します。そのURLをExcelに転記します。
注意点
- まれに、ボット判定されてアクセス拒否されるサイトがありました。(数百件に1件程度)
- 検索一位を取得するので、公式ページが仮に検索一位でない場合、別のページが取れてしまいます
- 処理速度は40件で9分程度です(非常に遅いです)
フロー全体
フロー全体像は以下のようになります。
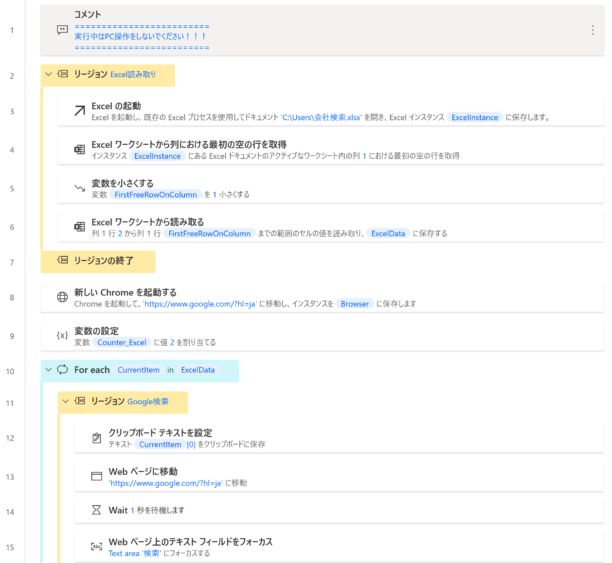
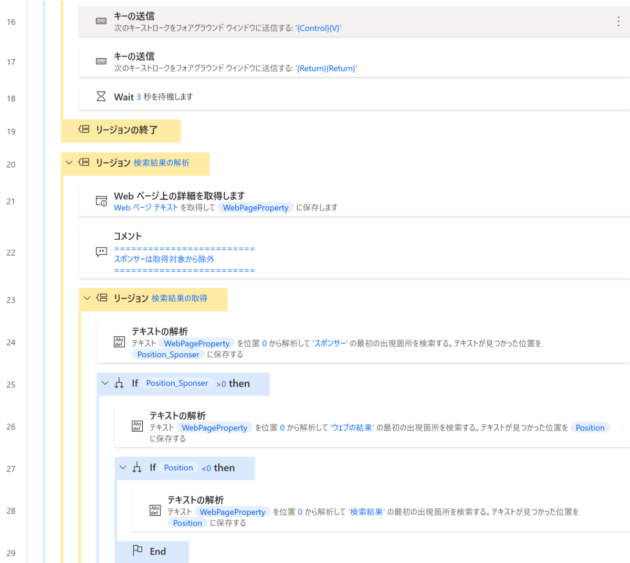
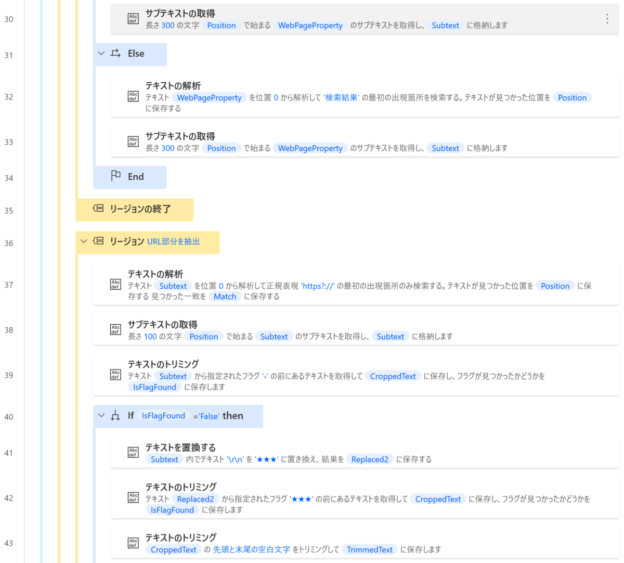
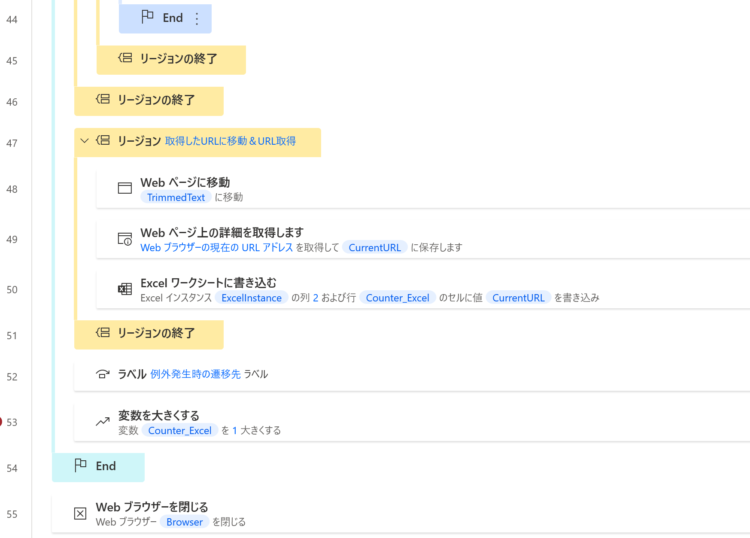
もし、本フローが欲しいという場合は、お問い合わせからご連絡いただければメールにてテキスト形式のファイルで共有します。(テキスト形式のファイルからコピペにて、フローをコピーすることが可能です。やり方が分からない場合も聞いていただければご案内します)
まとめ
今回は、Google検索結果の一位を正確に取る方法について解説しました。
Google検索結果の一位は、構造が毎回変わったり、スポンサーが入ることもあり、前回紹介した内容だけではうまく取り切れないことがあると思います。
本フローは少し長いのと、正規表現などいろいろ細かな設定があり少し難しいですが、こちらの方法で行えば正確に一位のURLのみ取得できますので、会社検索や商品リサーチなどに生かしていただければと思います。



コメント