
今回は、Python in ExcelでPandasを使う方法について解説します。
なお、Python in Excelの基本的な使い方については以下記事をご参照ください。

Pandasはデフォルトでインストールされている
Python in Excelでは、Pandasはデフォルトでインストールされています。そのため、PY関数のなかで
import pandas as pd上記のようなインポート文を書く必要はありません。(書いても動きます)
Pandasの概要について
Pandasとは、Pythonのライブラリのひとつで、データ分析を容易にする機能を提供しています。
- データの操作:(データの選択、フィルタリング、ソート、グループ化、集約など)
- データのクリーニング(欠損データの処理、重複データの削除、データの変換)
- データ統計・分析:平均、中央値、標準偏差などの基本的な統計から、相関、回帰などの高度な分析
データ分析ではNumpyというライブラリもよく使われますが、Numpyは計算に特化、Pandasは扱えるデータ幅が広いという違いがあります。
※ライブラリとは何か?についてはこちら参照
Python in Excelで使うメリットは?
Python in ExcelでPandasを扱えることのメリットとしては、以下が挙げられます。
Excelのテーブルをそのまま元データにできる
Pandasでは、ExcelをDataFrameとして読み込むことができます。このとき、
- 必要なライブラリをインポートする
- read_excel関数を使用して、Excelファイルを読み込む
という手順が必要です。しかし、Python in Excelでは、Excelのテーブルを指定するだけでDataFrameを作成することが可能です。
Excelの便利な機能を活かせる
Python in Excelでは、Pythonライブラリの便利な機能を享受しつつ、Excelの様々な便利機能を活用できます。
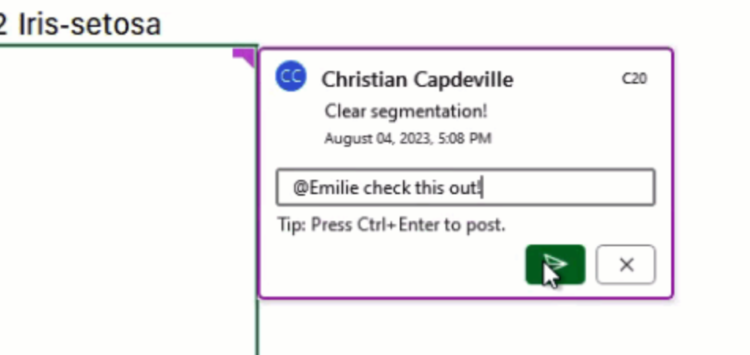
たとえば、ファイルの共有機能を使えば、Pythonコードを設定したセルに対してコメントを追加したり、ファイルを共同編集することができます。
Pandasのデータ構造
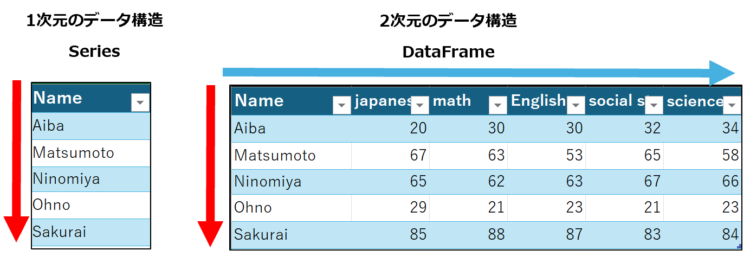
Pandasのデータ構造は、主に以下の2種類です。
- Series(1次元のラベル付き配列)
- DataFrame(2 次元のラベル付きデータ構造)
以降でそれぞれ解説します。
Series:1次元のデータ
Seriesの基本構文は以下の通りです。
pd.Series(data, index=index)
※data:リスト、ディクショナリ、ndarray
※index:省略可。省略すると0から始まる整数のインデックスになる
例1:リストからSeries作成、index省略
以下は、リストをdataに渡してSeriesを作成した例です。
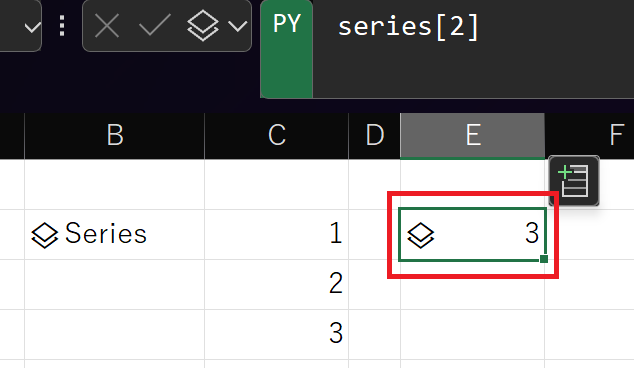
list = [1,2,3]
series = pd.Series(list)Python in ExcelのPY関数に上記のコードを入れると、以下のように一次元の表が生成されます。

インデックスは省略して宣言したので、インデックスは0、1、2となっています。実際に、インデックスを指定してSeriesの中身を取り出して見ます。
series[2]インデックスの2、つまり3番目の値が取得されます。
例2:ディクショナリから作成
以下は、ディクショナリを渡してSeriesを作成した例です。
sample_dict = {'name': 'Sakurai', 'age': 41, 'city': 'Tokyo'}
series = pd.Series(data= sample_dict)
series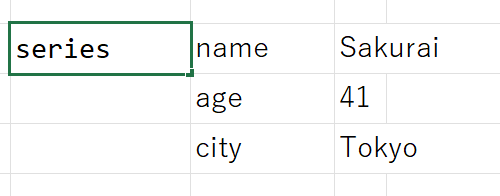
ディクショナリの場合、ディクショナリのキーがインデックスとなりますので、以下のようにして取り出すことができます。
series['age']もちろん、series[1] でも取り出すことは可能です。
DataFrame:2次元のデータ
DataFrameの基本構文は以下の通りです。
pd.DataFrame(data, index=行名, columns=列名)
※data:リスト、ディクショナリ、ndarray、Series、Excel等のファイル、スクレイピング結果など
※index、columns:省略可。省略すると0から始まる整数のインデックスになる
Pandasでデータを扱う際は、DataFrameで行うことが多いです。二次元のデータ構造で、Excelの表をイメージすると分かりやすいです。文字列や数字などのいろんなデータを持つことができます。
行名・列名の指定
DataFrameでは、行名(index)・列名(colums)がそれぞれつけられており、それをもとにデータを取り出すことが可能です。
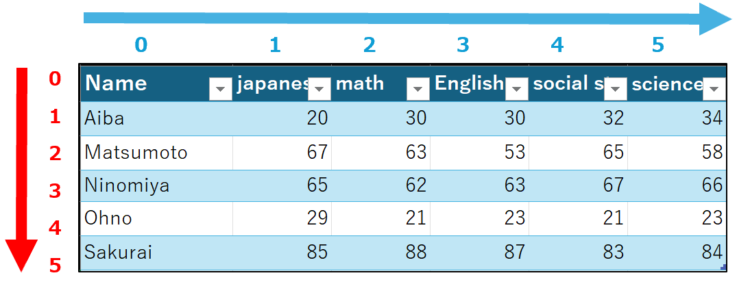
インデックスを指定しない場合、0から始まる整数になります。
例1:リストからDataFrame作成
以下は、リストをもとにDataFrameを作成した例です。
data = [
[1001, 'Aiba', 'Chiba'],
[1002, 'Matsumoto', 'Tokyo'],
[1003, 'Ninomiya']
]
df = pd.DataFrame(data, columns=['Number', 'Name', 'City'])columsには列名(インデックス)がつけられています。index(行名)は省略されていますが、内部的には0,1,2…というインデックスを持ちます。

ExcelのテーブルをPandasのデータとして扱う
Python in Excelでは、Series・DataFrameを作成する際に、Excelのテーブルをデータに指定することができます。
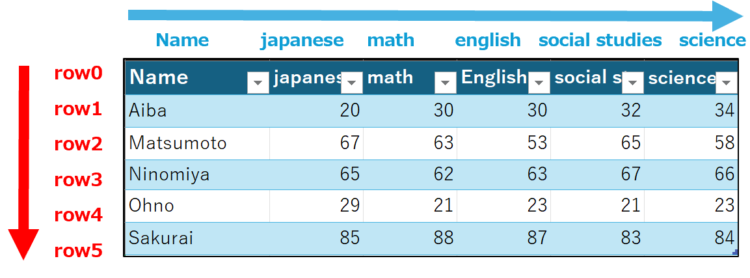
以下のようなテーブルを例として、DataFrameとして扱う手順を解説します。
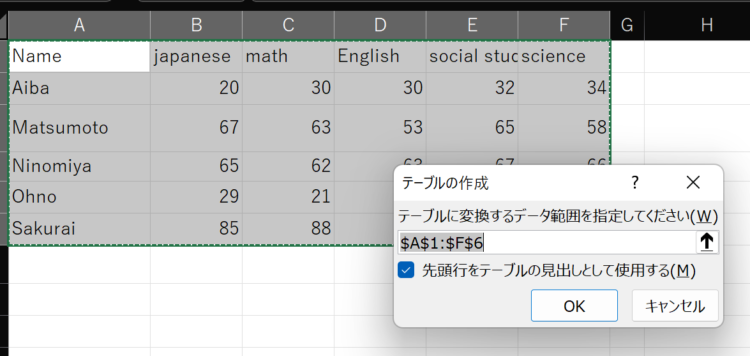
【STEP1】表をテーブル形式にする
Python in ExcelでPandasのSeriesやDataFrameを扱う場合、Excelの表はテーブル形式になっている必要があります。
表になっている範囲を選択して、挿入>テーブルを押します。
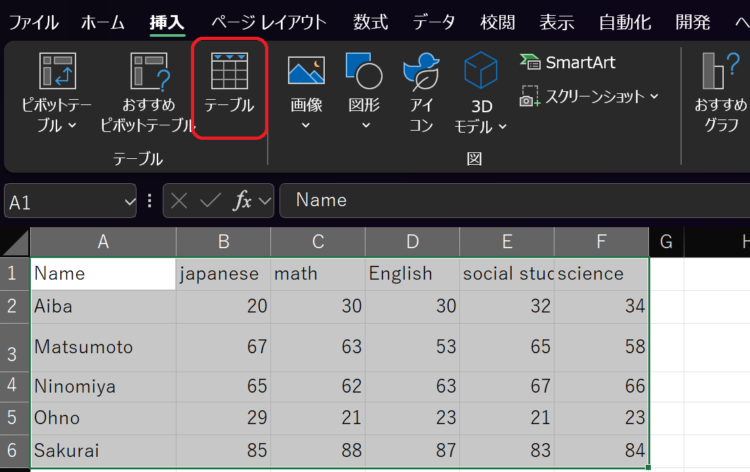
データ範囲を確認の上、OKを押します。
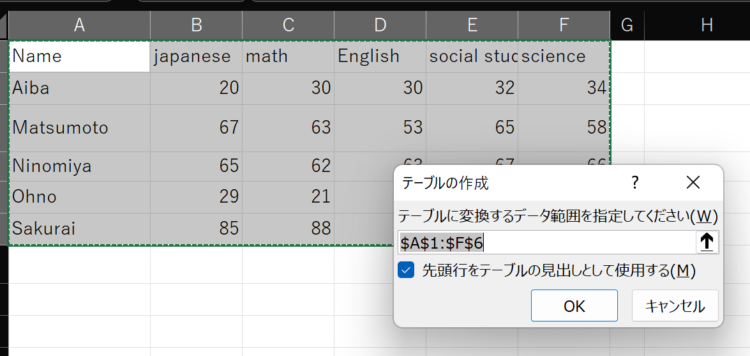
これでテーブルになりました。
【STEP2】テーブル範囲をDataFrameとして取得する
次に、テーブル範囲をDataFrameとして取得します。これを行うことで、Excel上でDataFrameに対してPandasのライブラリを使って操作することができるようになります。
任意のセル上で、「=PY(」と入力するか、

数式>Pythonの挿入を選択します。
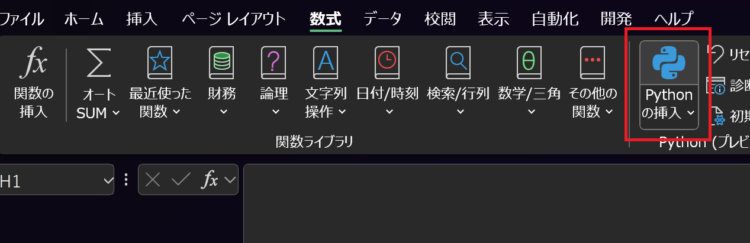
すると、以下のようにセルに「PY」と表示されます。
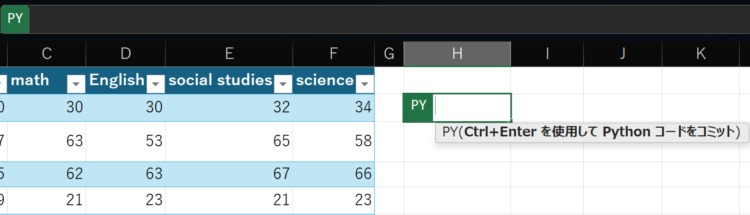
この状態で、DataFrameとして扱いたい範囲を選択します。選択するとPY関数内に自動でコードがセットされます。
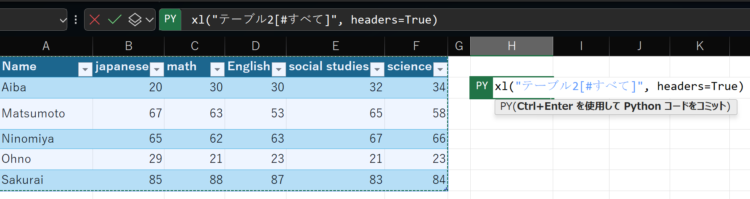
この状態で、Ctrl+Enterを押してコードを実行すると、セルに「DataFrame」というアイコンが表示されます。
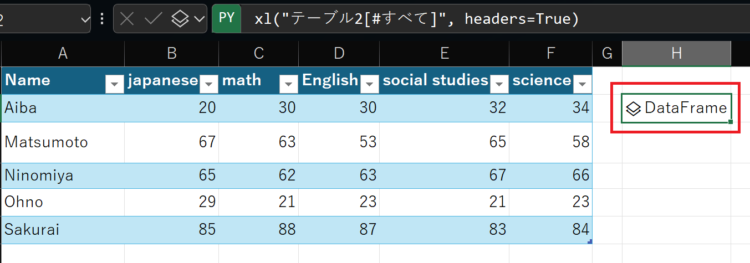
Excelのテーブルは、DataFrameとして扱われます。
SeriesやPython標準のリスト等として扱いたい場合は、一度DataFrameとして取得したあとに加工する必要があります。
【STEP3】作成したDataFrameに対する操作
STEP2で作成したDataFrameに対して操作します。
DataFrameに対して色々操作をするにあたり、先ほど作成したコードを以下のように変更しておきます。
【変更前】 xl("テーブル2[#すべて]", headers=True)
【変更後】 df = xl("テーブル2[#すべて]", headers=True)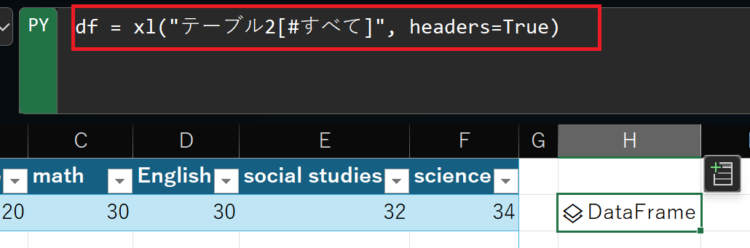
こうすることで、別からdfという変数として参照することができるようになります。
Seriesに変換
先ほど作成したDataFrameを、Seriesとして扱うパターンを考えます。
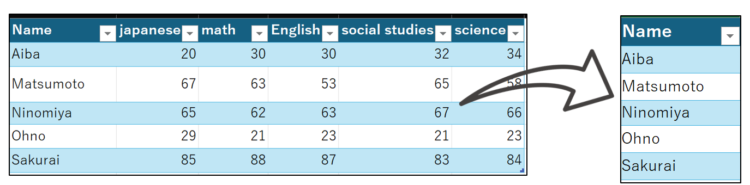
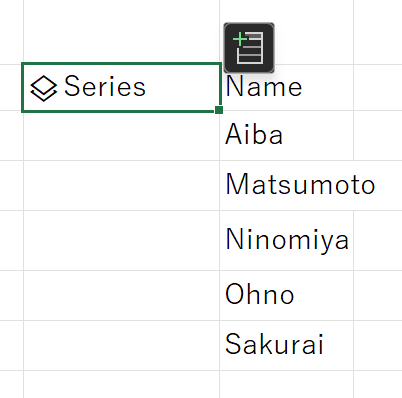
任意のセルに、以下のコードを入力します。
df['Name']Nameの列が抽出され、オブジェクトはSeriesとなりました。
query:データのフィルタリング
df.query()では、条件式を使用してDataFrameからデータをフィルタリングします。
df.query("20 <= math <= 40 and English == 30")mathの値が20以上40以下、Englishが30であるデータのみフィルタリングされました。

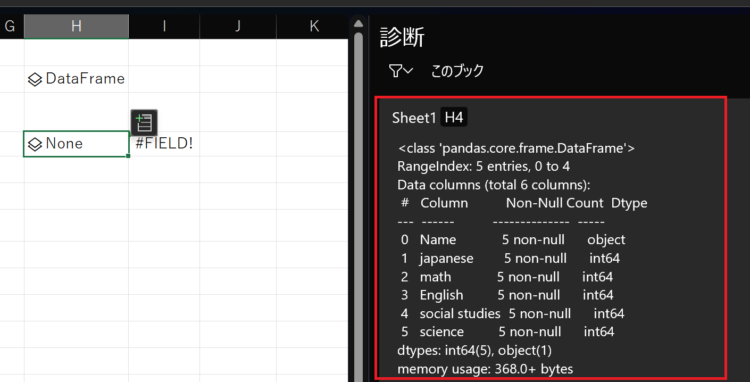
info:データ型・欠損値の情報を出力
df.info()では、DataFrameのカラム数、各カラムの情報(カラム名、非欠損値の数、データ型)、メモリ使用量などの情報を提供します。
df.info()ただ、これを実行してもExcelのセル上には表示されません。

出力系は「診断」エリアに表示される
Python in Excelでは、Printやloggingなどの出力処理は、「診断」というエリアに表示されます。
describe:要約統計量(平均・標準偏差・最小値・最大値)
df.describe()では、DataFrameの各数値型カラムに対して基本的な統計的情報を提供します。
df.describe()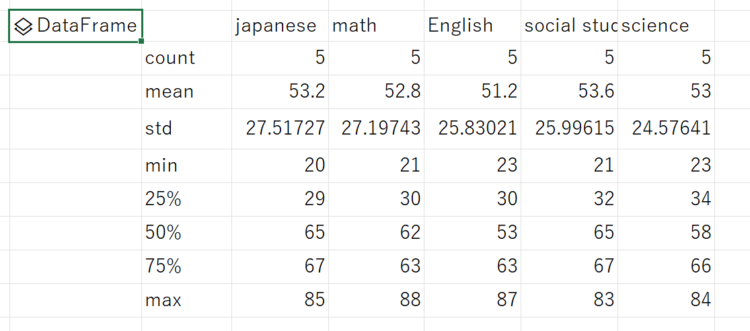
まとめ
今回は、Python in ExcelでPandasを使う方法について解説しました。
Excelのテーブルを指定するだけでDataFrameとして扱うことができるのは便利だなと思いました。次回は、より実用的な操作について例を交えながら解説できたらと思います。
参考:
Announcing Python in Excel: Next-Level Data Analysis for All


コメント