
本記事では、Seleniumを使ってリンクタグからURLを取得する方法を解説します。
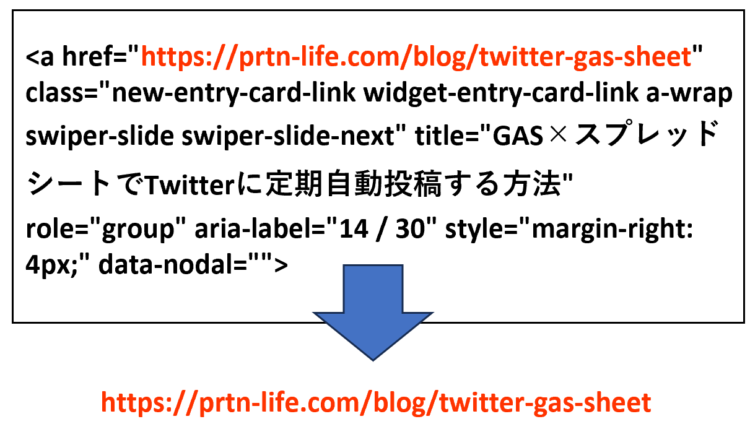
なお、本記事ではChromeDriverを用いて、Google Chromeを自動操作しながら解説していきます。
やりたいこと
ブラウザを自動操作できるツールである「Selenium」を使って、Webサイト内のリンクのURLを取得したいと思います。
例えば、Yahoo!JAPANのホームページの「ショッピング」というリンクについて見てみます。
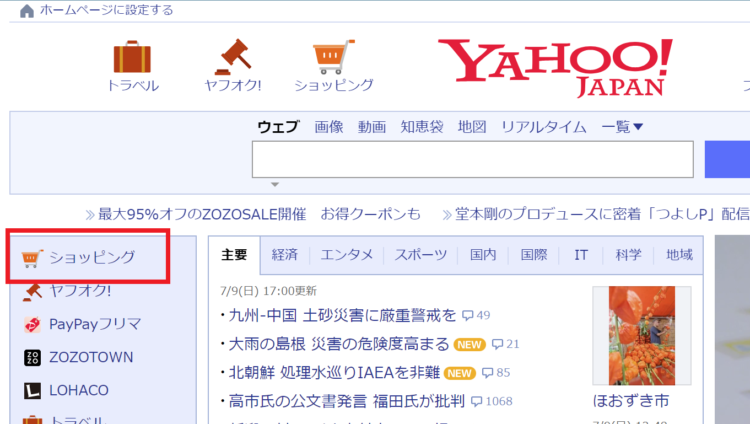
「URL」というのは、リンクになっている部分のURLをさします。上記の場合は「https://shopping.yahoo.co.jp/?sc_e=ytc」です。
Seleniumを用いて、自動で取得する方法を解説します。
事前準備:Seleniumのインストール
まず、SeleniumとWebDriverをインストールします。
設定手順については、以下記事をご参照ください。

タグの「要素」と「属性」について
HTMLの形式は、Webサイトによって異なります。そのため、ネットに記載の内容をそのままコピペしても動かないこともあります。
今回は、まず初めにおさえておきたいHTMLの構造について簡単に説明します。これを取得したいWebページに置き換えて考えていただければと思います。
要素とは?
要素とは、HTMLのタグで囲まれた部分をさします。ここからここまでが一つのブロックだよというのを表し、そのタグによってフォントサイズや文字色、画像の表示などを行います。
<p>これが要素です!</p>属性とは
属性とは、タグの追加設定です。
<a href="https://www.example.com">ここをクリック</a>「href」が属性にあたります。aタグはリンクを表すタグであり、リンク先がオプションとしてhrefで指定されています。値は「属性値」といいます。
HTMLタグからURLを取得するには、以下のような手順になります。
- 要素の取得
- 属性を指定してURLを取得
【STEP1】Webサイトを開く
SeleniumとWebDriverのインストールが完了したら、さっそく自動操作のためのコードを書いていきます。
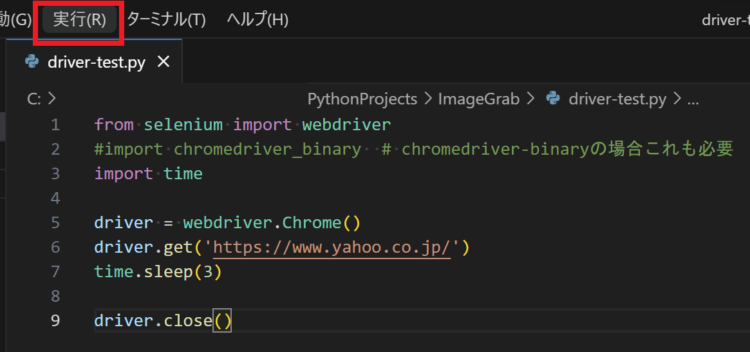
まずは、指定のWebサイトを開いて閉じるだけのコードを実行してみます。
from selenium import webdriver
# import chromedriver_binary # chromedriver-binaryの場合これも必要
import time
driver = webdriver.Chrome()
driver.get('https://www.yahoo.co.jp/')
time.sleep(3)
driver.close()上記を、PyCharmやVisual StudioなどのIDEか、VSCodeなどのエディタなどに貼り付けます。「実行(Run)」ボタンを押して実行します。
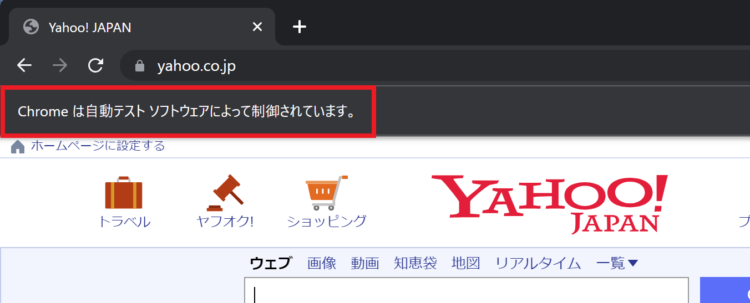
Yahoo!JAPANが表示され、3秒開いたあと閉じたらOKです。なお、webdriverで実行する場合、画面上部に「Chromeは自動テストによって制御されています。」と表示されます。
【STEP2】リンクを含む要素を取得する
URLを取得するには、まずリンクを含む要素を取得する必要があります。
以下は、Yahoo!JAPANのトップページのHTMLの一部です。
<a class="yMWCYupQNdgppL-NV6sMi _3sAlKGsIBCxTUbNi86oSjt cl-nofollow" href="https://shopping.yahoo.co.jp/?sc_e=ytc" aria-label="ショッピングへ遷移する" data-cl-params="_cl_vmodule:tool;_cl_link:shopping_1;_cl_position:1;svcid:1" data-cl_cl_index="1"><p class="_2bBRLhI5ZpVYu0tuHZEFrn"><span class="pz0On1w4yAviBGMdKItoQ"><span class="fQMqQTGJTbIMxjQwZA2zk _3tGRl6x9iIWRiFTkKl3kcR">ショッピング</span></span><span class="_1Al3K70np2V_Ev1eGkfsBm"><span class="_2Uq6Pw5lfFfxr_OD36xHp6 _1dr5aVDbNPF63JCS2bJhij MOLSPrtOUmdnYy_LgNt2f" style="width:20px;height:20px"></span></span></p></a>URL部分だけ取り出す際、hrefだけをいきなり取り出すことはできません。なぜなら、hrefはHTMLタグの「属性(オプション)」だからです。まず、タグを取得してから属性値を取り出します。
◆ HTML要素を取り出す
driver.findElement(By.XPATH(“Xpath文字列”));
でいったんaタグを含む要素を取得します。By.XPATH以外にも、
- find_element(By.ID, “xxx”)
- find_element(By.NAME, “xxx”)
- find_element(By.CLASS_NAME, “xxx”)
等で要素の取得は可能です(参考:Seleniumクイックリファレンス>要素の取得について)。
from selenium import webdriver
#import chromedriver_binary # chromedriver-binaryの場合これも必要
import time
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://www.yahoo.co.jp/')
time.sleep(3)
elem = driver.find_element(By.XPATH, '//*[@id="ToolList"]/ul/li[1]/div/a')
driver.close()上記はYahoo!JAPANの「ショッピング」のHTML要素をXPATHで取得した例です。水色の箇所が追加した部分です。
【STEP3】リンク部分のみ抽出
STEP2で取得した要素のなかから、URL部分のみを抽出します。
◆ 属性を指定してURLを取り出す
driver.get_attribute(属性名);
from selenium import webdriver
#import chromedriver_binary # chromedriver-binaryの場合これも必要
import time
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://www.yahoo.co.jp/')
time.sleep(3)
elem = driver.find_element(By.XPATH, '//*[@id="ToolList"]/ul/li[1]/div/a')
url = elem.get_attribute('href')
print(url)
driver.close()上記の実行結果は以下になります。
https://shopping.yahoo.co.jp/?sc_e=ytcelem = driver.find_element(By.TAG_NAME, ‘a’).get_attribute(‘href’) じゃダメ?
⇒ find_elementでタグ名から要素を取得することは可能ですが、aタグが複数存在する場合最初の要素しか取得できません。
うまく取得できない場合
うまく取得できない場合、何等かの原因で要素が特定できていない可能性があります。トラブルシューティングについては以下記事をご参照ください。

まとめ
今回は、Seleniumを使ってリンクタグからURLを取得する方法を解説しました。
HTML要素の取り出し⇒属性を指定して属性を取得という手順でURLを取得できることが分かりました。JavaScriptやiframe等で作られたページの場合は、本記事の手順通りに指定してもNoSuchElementExceptionエラーで取得できない可能性もあります。そのような場合の対処法は別途まとめようと思います。
本記事が参考になれば幸いです。



