
今回は、SeleniumでXPathを指定して要素を取得する方法を解説します。
XPath指定ができるようになると、Classやnameなどで指定してもうまく要素を取れない場合にも取得できたり、リストやテーブルの特定の行・列のみ取得するなど、要素を柔軟に取得できるようになります。
初心者の方にも分かるよう、基礎的な部分から解説していきますので参考になればうれしいです。
XPathとは
XPathとは、XML Path Langageの略で、XMLやHTML形式の文書から特定の部分を指定するときに使う構文です。PCのファイルパスのようなイメージです。
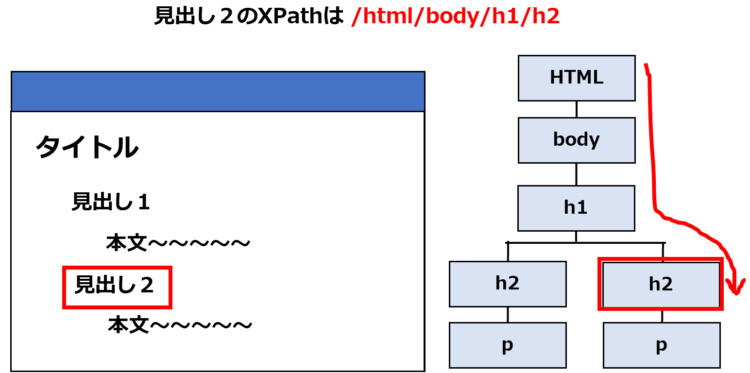
XPathはどんなときに使う?
要素の取得には、find_elementメソッドを使いますが、引数にはBy.id、By.name、By.tagName等様々な指定方法があります。では、XPathはどのようなときに使うかというと、
- idやclassなどでうまく要素を取得できないとき
- そもそもidやclassなどがない場合
- idやclassなどで要素を一意に特定できない場合
などに使うと便利かと思います。それ以外でもXPathであれば、開発者ツールでコピーして貼り付けるだけなので楽です。HTMLの構造を表す記述のため、後から見返したときにどの要素を指定しているのかも分かりやすいです。
XPathは省略した形になっていることが多い
XPathには省略構文があります。
例として、Yahoo!JAPANのトップページ右上にある「Yahoo!BB」のXPathで考えます。
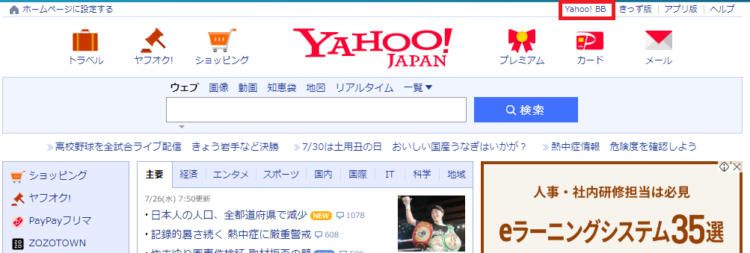
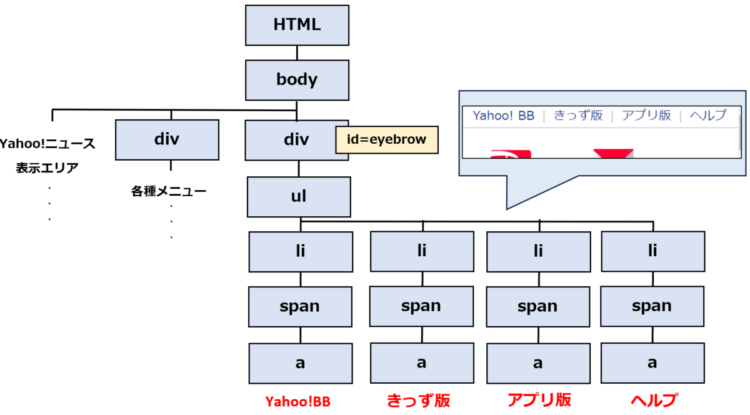
HTMLは、<div>などのタグで囲まれた部分がひとつの要素として、ツリー構造になっています。ここから、Yahoo!BBの場所を指定するには、一番先頭のHTMLから辿っていきます。
「Yahoo!BB」のXPathは、フルパスで書くと以下のようになります。
/html/body/div[1]/div/header/div[1]/ul/li[1]/span/aこのように、先頭から全て表記すると長くなってしまうため、途中までのパスを省略することがあります。省略した形が以下です。
//*[@id="eyebrow"]/ul/li[1]/span/aフルパスのほうでは先頭から順に辿っているのに対して、省略形ではid属性から始まっています。
XPathの省略記法
開発者ツールでXPathを取得する際は、取得した内容をそのままソースコードにコピペすればOKではありますが、よく使われるものを載せておきます。
| 記法 | 内容 | サンプル |
|---|---|---|
| // | ノードの子孫すべて | //h2 h2の要素すべて |
| @ | 属性名を指定 | //h1[@class] class属性を持つ要素 |
| * | すべての要素 | //*[@class=”test”] class名が”test”の要素すべて |
XPathの調べ方
対象となるWebページで右クリック>検証を押します。
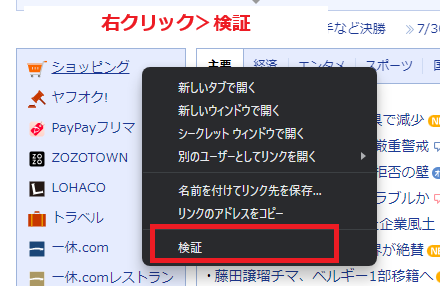
※対象となる要素の上で右クリックすると、HTMLを開いた際に要素がハイライトされます。
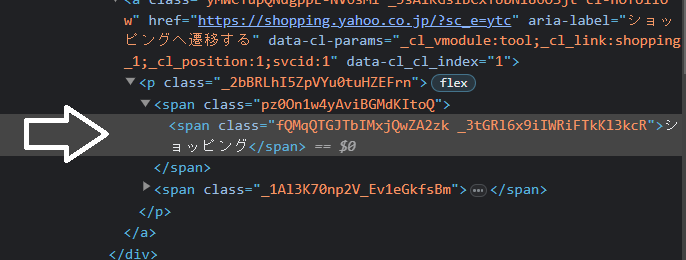
もしくは、開発者ツールに入ってから一番上の矢印アイコンを押し、取得したい要素にカーソルを当てても同様のことができます。
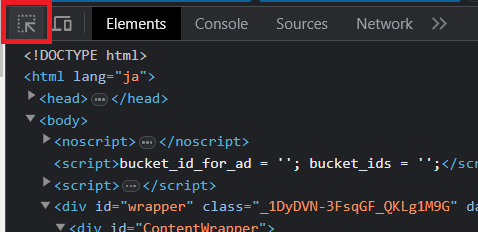
取得したい要素にカーソルが当たっている状態で、右クリック>Copy>Copy XPathを選択します。
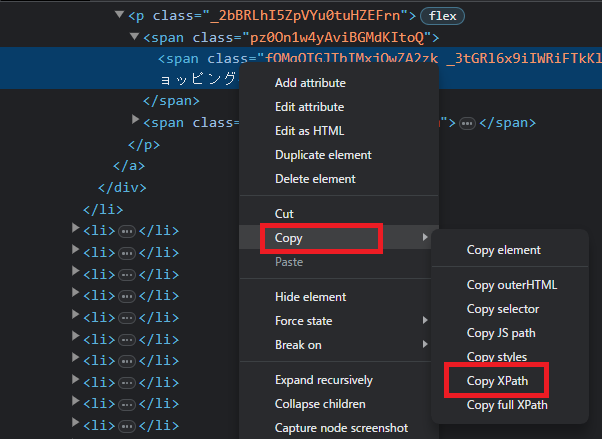
これで、XPathを取得することができました。
XPathで要素を取得する方法
XPathで要素を取得する方法は、以下になります。
◆要素の取得(単数) ※戻り値は要素
driver.findElement(By.XPATH, ‘ここにXPathを入れる’)
◆要素の取得(複数) ※戻り値は要素のリスト
driver.findElements(By.XPATH, ‘ここにXPathを入れる’)
要素の取得(単数)
findElementメソッドでは、要素をひとつだけ取得します。同じ要素名が複数存在する場合、最初の要素だけ取得されます。
from selenium import webdriver
#import chromedriver_binary # chromedriver-binaryの場合これも必要
import time
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://www.yahoo.co.jp/')
# ページが開くまで3秒待機
time.sleep(3)
# 要素をXPathで取得
element = driver.find_element(By.XPATH, '//*[@id="ToolList"]/ul/li[1]/div/a/p/span[1]/span')
# 「ショッピング」をクリック
element.click()
driver.close()要素の取得(複数)
findElementsメソッドでは、あてはまる要素すべてが取得されます。戻り値はリストになります。
# 要素をXPathで取得
element = driver.find_elements(By.XPATH, '//*[@id="ToolList"]/ul/li/div/a/p/span[1]/span')
for el in element:
print(el.text)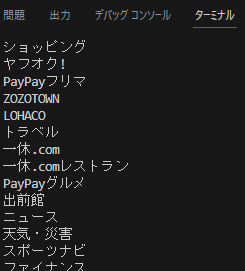
複数要素を取得したい場合のXPath記述
以下のような、複数のファイルを全て取得したい場合について考えます。
いくつか適当に要素を取得してみると、以下のようにtdの部分が異なっていることが分かります。
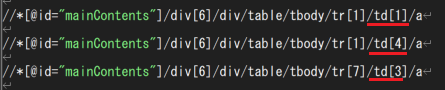
tdというのはtable dataの略で、テーブルのセルを指します。つまり、tdのセル位置を指定せずに記載することで、すべての要素を取得することができるようになります。
//*[@id="mainContents"]/div[6]/div/table/tbody/tr/td/aXPathで指定した要素が見つからない場合
要素の取得に失敗する場合は、以下の原因が考えられます。
SyntaxError
SyntaxError: Failed to execute 'evaluate' on 'Document': The string '///[@id="mainContents"]/div[6]/div/table/tbody/tr/td/a' is not a valid XPath expression.こちらはXPathの記述方法に間違いがある場合に発生するエラーです。上記の例では「///」とスラッシュが3本になっています。
エラーはでないが要素が取得できていない
指定した要素がなかった場合、エラーなく終了します。構文エラーではないけど、正しいXPathを記述できていない場合に起こります。
参考:トラブルシューティング
find_elementメソッド実行時のエラーは上記以外にも、iframe内の要素を操作しようとしていたり、要素がjavascriptになっていたりする場合に発生します。
詳しくは以下記事で解説しています。

まとめ
今回は、SeleniumでXPathを用いて要素を取得する方法について解説しました。
XPathは、最初はちょっと抵抗ある方もいらっしゃるかもしれませんが、使えるようになるととても便利です。特に、スクレイピングをしたいという場合はおさえておくと役に立つと思います。



コメント