
今回は、GASでWebスクレイピングする方法を初心者向けに解説します。
このページにアクセスしていただいているということは、「このページのここを取得したい!」「競合リサーチを効率化したい!」などの目的を既にお持ちの方が多いかと思います。
スクレイピングに関しては、記事に載っている内容をそのままコピペして終わりではなく、ご自身が取得したいページの内容に変更する必要があります。そのため、初心者の方には難しいと感じられるかもしれません。
そこで、本記事では、このページを読んだ方が実際に自分でスクレイピングのコードが書けるようになることを目標に、わかりやすく解説していきたいと思います!
Webスクレイピングとは
以下は、とある会社のホームページのHTMLです。
ここから、講演スケジュールだけを取得するという操作が「スクレイピング」にあたります。
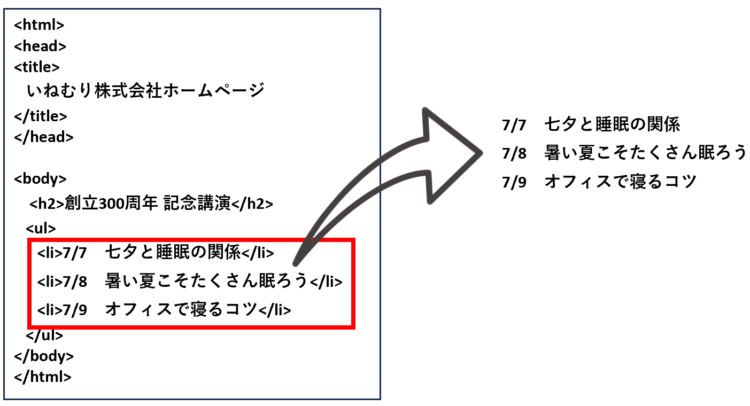
この、HTML要素から特定の要素を取り出す操作を行うのに「Goole Apps Script(GAS)」などのプログラミング言語が使われます。スクレイピングを活用することで、わざわざホームページにアクセスして欲しい情報をコピペしたり、情報が更新されていないかどうか見に行ったりする必要がなくなります。
スクレイピングとは、Webページから欲しい情報を取得して解析・加工する技術のこと。
自分でWebサイトを操作する手間を省き、効率化・自動化がはかれる。
Google Apps Script(GAS)の事前準備
では、さっそくGoogle Apps Script(GAS)でスクレイピングをしていきましょう。
「GASを触ったことない!どうやって使うか分からない・・!」という方は、こちらの記事をさらっと読んでから以降に進むとスムーズかと思います。
Parserライブラリのインストール
GASでHTML解析をする場合、「Parserライブラリ」を使うと簡単に行うことができます。Parserライブラリを使用する際はインストールが必要です。
GASのエディタ左側メニューにある「ライブラリ」の+マークを押します。
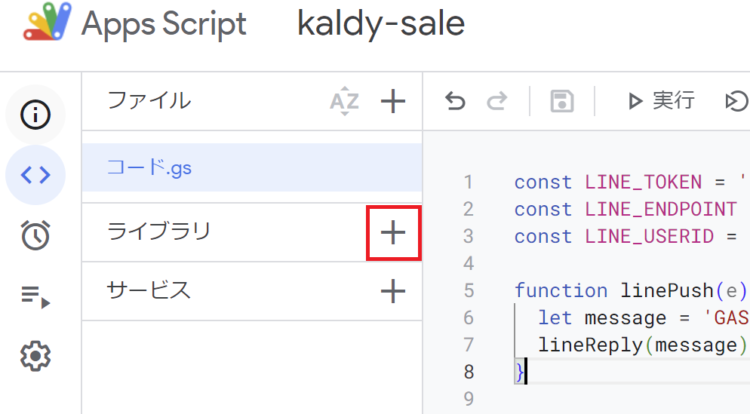
「スクリプトID」に以下を入力し、「検索」を押します。
1Mc8BthYthXx6CoIz90-JiSzSafVnT6U3t0z_W3hLTAX5ek4w0G_EIrNw
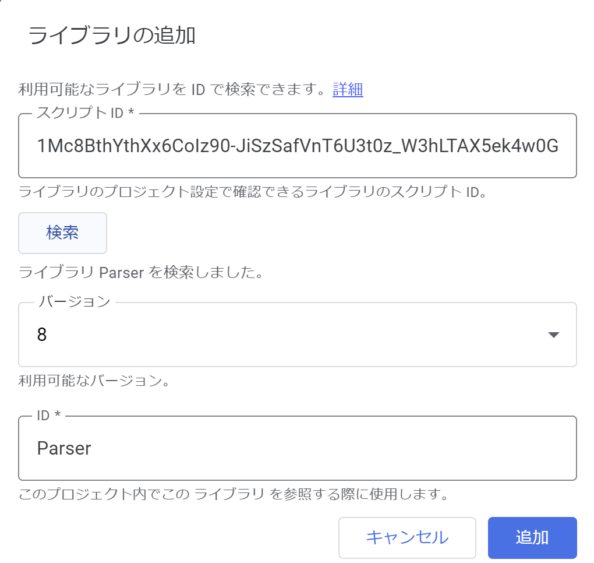
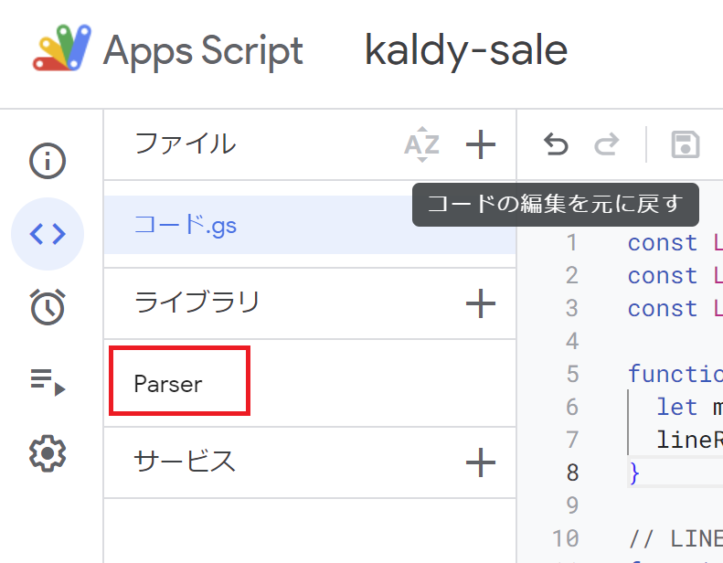
「追加」を押して、メニューにParserが追加されていることを確認できたらOKです。
【STEP1】スクレイピング前に確認すべきこと
スクレイピングをするにあたり、はじめに確認すべきことを記載します。
よく分からないままスクレイピングを行うと、サーバーに負荷をかけたり、規約違反・著作権侵害となる可能性がありますので、十分に注意して行うようにしましょう。
スクレイピングしていいサイトか確認
まず、対象のサイトのトップページを開きます。ブラウザの上のほうにURLが表示されているので、その末尾でクリックします。
末尾に、「/robots.txt」と追加します。
すると、以下のような画面に遷移します。
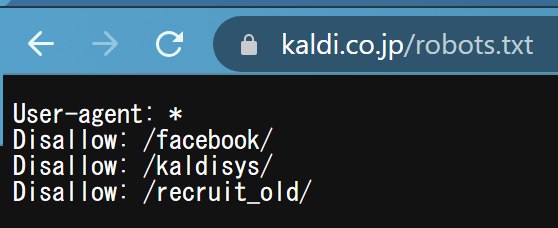
1行目の「User-Agent:*」は、全てのクローラー(ロボット)を許可、2行目以降の「Disallow」は特定のドメインは許可していない、という意味です。
なお、robots.txtは必ず記載があるわけではありません。Webページ上の利用規約をあわせて確認するようにしてください。
アクセス頻度に注意する
スクレイピングを行う場合、サーバーに負荷をかけないようアクセス頻度に注意する必要があります。アクセス頻度に明確なルールはありませんが、人間が手でできるくらいのスピード・間隔で行うようにするのが良いでしょう。
ちなみに、過去には1秒につき1回、1日2000回のアクセスを行った男性が偽計業務妨害で逮捕されています(Librahack事件)。
【STEP2】対象のサイトからHTMLを取得
STEP1で、スクレイピングして良いサイトだということが分かったら、実際にスクレイピングの処理を実装していきます。
スクレイピングのおおまかな手順は以下の通りです。
- WebサイトのHTMLを取得 (UrlFetchApp)
- 取得したHTMLの中から必要な部分を取り出す (Parser)
- 取り出したものを加工する
まず、対象となるWebサイトからHTMLを取得します。この時点では特定の要素を取り出したりはせず、HTMLをまるっと取ってくるイメージです。
GASでHTMLを取得するコード
GASでHTMLを取得するには、以下のように記載します。
UrlFetchApp.fetch(URL).getContentText(“[文字コード]”);
※文字コード:headタグ内の <meta charset=”[文字コード]”> にあわせる
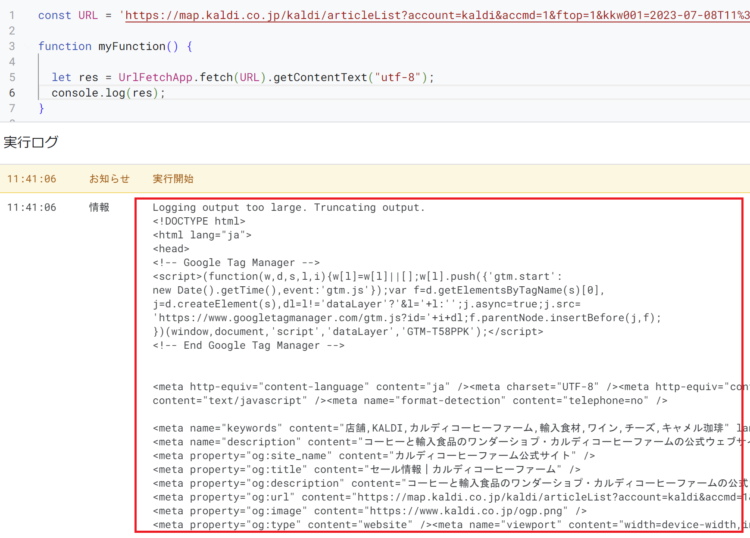
例えば、カルディのセール店舗一覧ページのHTMLを取得するコードは以下のとおりです。
const URL = '取得したいページのURL';
// 対象のURLのHTTPレスポンスを取得
let res = UrlFetchApp.fetch(URL).getContentText("utf-8");
// 取得内容をログに出力
console.log(res)この処理によって、HTMLをそのままごっそり文字列として取得することができます。
【STEP3】HTMLの特定部分のみ抽出
STEP2では、対象のWebページのHTMLをごっそり取得しました。ここから、必要な部分だけ取り出します。
◆条件に一致する全ての要素を取得する場合(戻り値:リスト)
Parser.data(取り出し元).from(‘開始文字列’).to(‘終了文字列’).iterate();
◆条件に一致する最初の要素を取得する場合(戻り値:文字列)
Parser.data(取り出し元).from(‘開始文字列’).to(‘終了文字列’).build();
例えば、以下のHTMLのうちタイトルを取得したい場合は以下のようになります。
<head>
<title>これはタイトルです!</title>
</head>// <title>~</title>で囲まれた最初の文字列を取得
let title = Parser.data(res).from('<title>').to('</title>').build();
// 取得内容をログに出力
console.log(title);【実行結果】
これはタイトルです!こうして必要な部分だけ抽出できたら、あとは目的に応じて処理を追加していくだけです。
iterate()とbuild()の使い分け
なお、上記では「.build()」を使いましたが、この場合は<title>~</title>で囲まれた最初の文字列のみ取得されます。つまり、以下のように二か所<title>タグで囲まれた箇所があっても、一つ目しか取得されません。
<head>
<title>これはタイトルです!</title>
</head>
<body>
<title>これもタイトルなんだなあ</title>
</body>条件に一致する全ての文字列を取得する場合には「.iterte()」を使います。
開始・終了文字列の指定方法
先ほどの例では、<title>から</title>までを取り出せばよかったので指定が簡単でした。
では、以下からURLだけを取り出したい場合はどうすれば良いでしょう・・・!?
<a href="https://prtn-life.com/blog/ruby-install" class="new-entry-card-link widget-entry-card-link a-wrap swiper-slide swiper-slide-active" title="【2023最新】Rubyの特徴とインストール方法(Windows)" role="group" aria-label="1 / 30" style="margin-right: 4px;" data-nodal="">
Parserライブラリは、HTMLテキストを文字列として操作することができます。そのため、開始と終了が一意に特定できさえすれば、タグになっていなくても取得できます。
let res = UrlFetchApp.fetch(URL).getContentText("utf-8");
let link = Parser.data(res).from('<a href="').to('" class=').build();
console.log(result)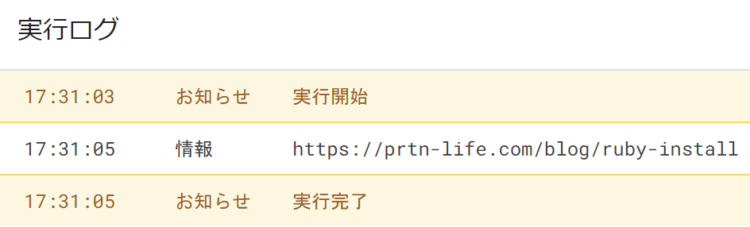
【STEP4】取得した要素を加工する
STEP3で取得した要素を加工します。
ここで、先ほど出てきたitelate()とbuild()の違いをおさらいしておきましょう。
◆iterate() で取得した要素:戻り値はリスト型
◆ build() で取得した要素 :戻り値は文字列
iterate()は条件に一致する全ての要素をリスト型で取得、build()は条件に一致する最初の要素を文字列で取得します。そのため、取得後の操作も異なります。
文字列の場合はそのまま文字列として加工することができますが、リスト型の場合は以下のようにループでそれぞれの要素を処理する形になります。
// 対象のWebサイトを取得のHTTPレスポンスを取得
let res = UrlFetchApp.fetch(URL).getContentText("utf-8");
// 記事一覧をリストで取得
let array = Parser.data(res).from('<div class="new-list">').to('</div>').iterate();
// リストの要素をループで取り出して処理
for (let i = 0; i < array .length; i++) {
// リストのi番目の要素をログに出力
console.log(array[i] );
}【応用1】テーブルの要素を取得する
以下はカルディのセール情報ページです。セール中の店舗が一覧になっています。
この中から、「柏市のセール情報だけ取り出したい」という場合、どうすれば良いか考えてみます。

HTMLのテーブル構造
HTMLのテーブルは、以下のような構造になっています。
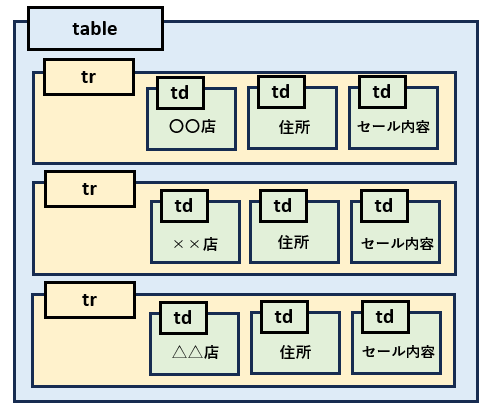
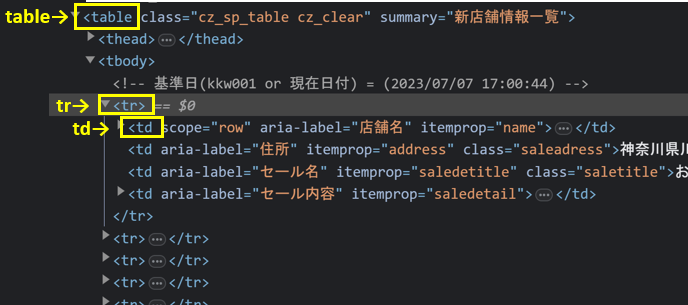
店舗ごとのデータがひとまとまりになっていて、それがいくつも並んでいるイメージです。
テーブル内の要素をリスト化する
テーブルになっている要素を取り出す際は、先ほども出てきた以下を使います。
◆条件に一致する全ての要素を取得する場合(戻り値:リスト)
Parser.data(取り出し元).from(‘開始文字列’).to(‘終了文字列’).iterate();
.itarate()は、条件に一致する全ての要素を取得しますので、<tr>ではじまって</tr>で終わる要素を全て取得し、それぞれをリストの要素として格納します。
let res = UrlFetchApp.fetch(URL).getContentText("utf-8");
let array = Parser.data(res).from('<tr>').to('</tr>').iterate();リストにしてしまえば、ループで回して条件に一致するものだけを取り出すことも可能になります。
for (let j = 0; j < array .length; j++) {
// ループ内処理を記載
}なお、テーブルの要素に関する操作はこちらの記事でも解説しています。
【応用2】トリガーで定期実行する
GASには「トリガー」という定期実行機能があります。これを使うと、毎日〇時、毎週月曜など、指定した間隔で自動実行することができます。
エディタの左側メニューにある時計のマークを押します。
トリガー設定のモーダルが表示されますので、希望のスケジュールを設定します。以下では週に一度実行するよう設定しています。
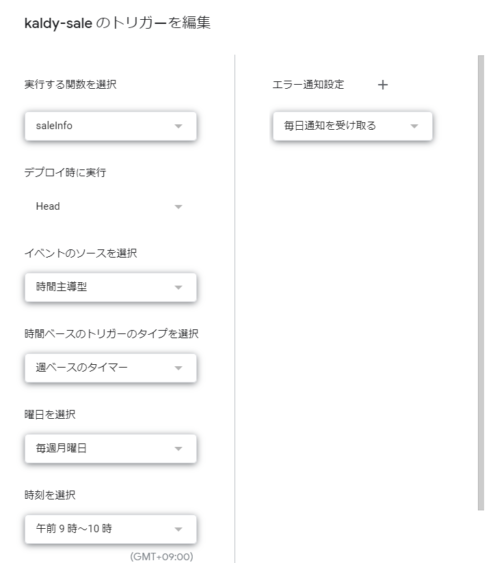
トリガーについては以下の記事にて詳しく解説しています。

GASスクレイピングの実例
GASスクレイピングを使った実例を紹介します。
ブログの最新記事をツイートする方法
以下は、ブログの最新記事を取得してツイッターに投稿する方法です。
各種Webサイトから、情報を取得 → ツイートの方法を理解することができます。

特定の条件に一致するデータだけを取得し、LINEに通知する方法
本記事でも例として少し載せましたが、店舗のセール情報をLINEで通知する方法です。

近隣店舗のセール情報が更新されたら、週に一度LINEに通知するようにしています(実際に使ってます)。こちらは先ほど紹介した「トリガー」機能を用いて定期実行しています。

まとめ
今回は、GASでWebスクレイピングする方法を初心者向けに解説しました。
HTMLの要素を取得・操作するのって、普段あまりHTMLを触らない方や、プログラミングをしない方は抵抗があるかもしれません。私自身もそんなに得意じゃないです。
また、どうしてもParserライブラリを使用する際はHTMLの中身を見て動かしながら加工していくかんじになるので、けっこう面倒だったりします。Pythonよりもスクレイピングに関するライブラリが豊富じゃないですしね。それでも、GASはネット環境さえあれば使えて、定期実行もできて、お手軽なので是非試していただければと思います。
「スクレイピングがうまくいかない」「こんな操作・加工がしたいけどどうすればいい?」などのご質問・ご相談がありましたら、コメントかお問い合わせからメッセージ頂ければ幸いです。



コメント