
Power Automate Desktop(PAD)の、「PDFからテーブルを抽出する」アクションの使い方について解説します。
対象とするテーブル
本記事にて対象とするテーブルは以下になります。赤枠の表の部分だけ抽出する方法について解説します。
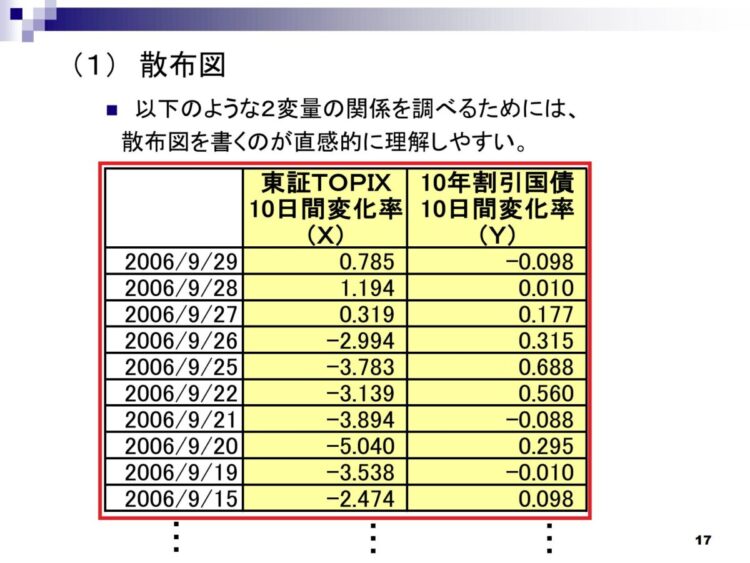
PADでPDFのテーブルを抽出する方法
PADでPDFのテーブルを抽出するには、以下のアクションを使います。
PDFからテーブルを抽出する
左側のアクション一覧から、「PDFからテーブルを抽出する」をドラッグアンドドロップで真ん中の白いエリアに配置します。
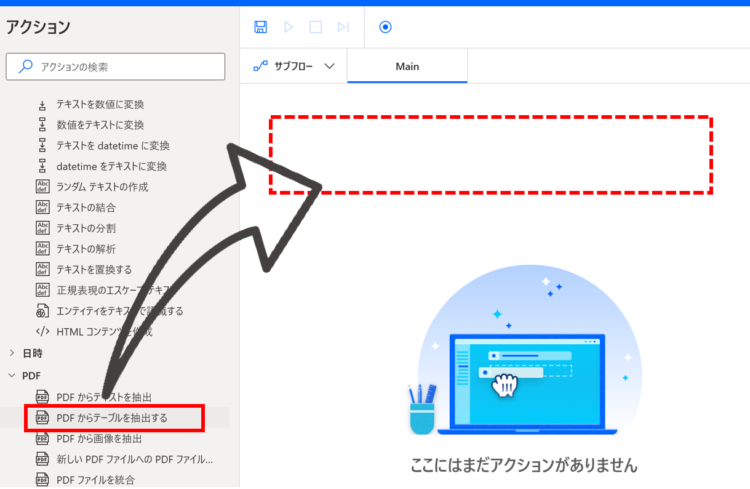
追加すると、以下のダイアログが表示されます。
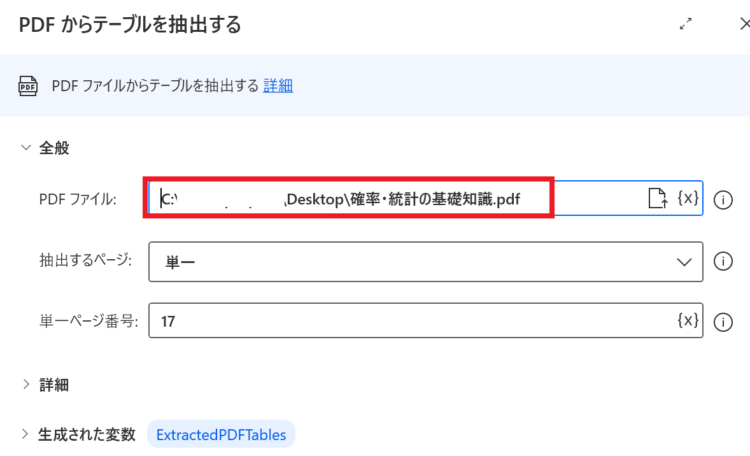
- PDFファイル:対象となるPDFファイルのフルパス
- 抽出するページ:すべて/ 単一/ 範囲 のいずれかから選択
フローを実行すると、「フロー変数」のExtractedPDFTablesという変数に値が入ります。
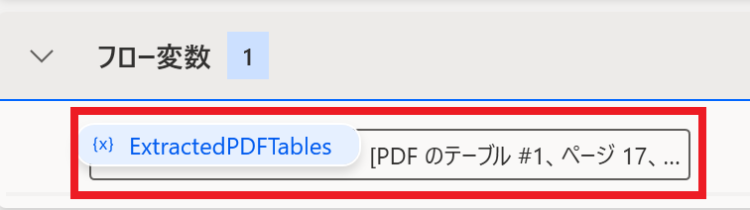
取得した表の取り出し方
取得した表を取り出す方法について解説します。
ExtractedPDFTablesという変数は、以下のような階層構造になっています。
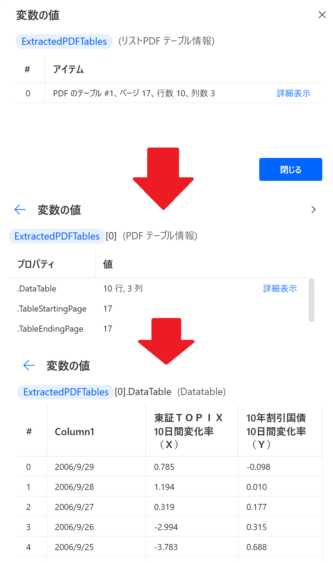
実際の表は、
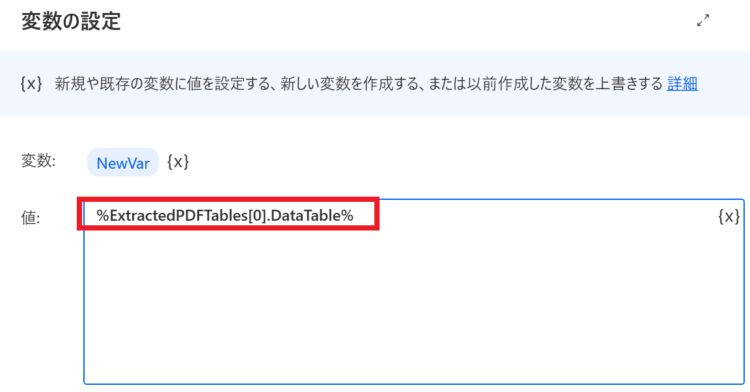
%ExtractedPDFTables[0].DataTable%で取り出すことができます。
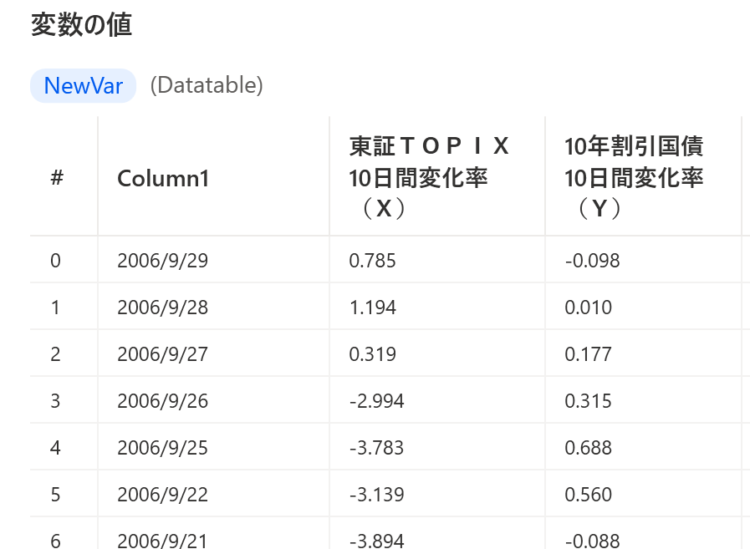
NewVarの値は、以下のようにデータテーブル型となります。
取得した表をExcelに転記する方法
PDFから取得したテーブルを、Excelに転記する方法は以下のようになります。
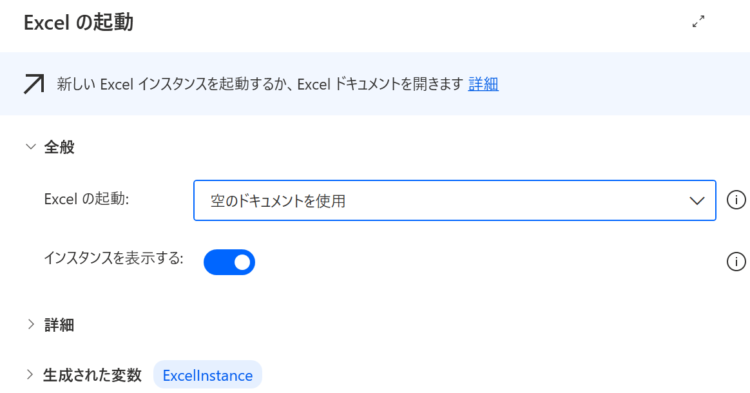
Excelの起動
Excelの起動
今回の例では空のExcelを起動していますが、既存のファイルを選択することもできます。
カラムの転記
Excelワークシートに書き込む
次に、「Excelワークシートに書き込む」アクションを追加します。
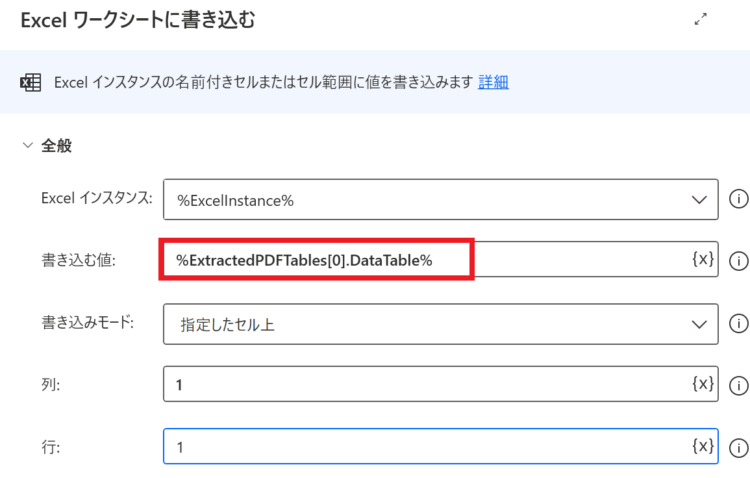
書き込む値に、
%ExtractedPDFTables[0].DataTable.ColumnHeadersRow%を設定します。列・行はそれぞれ1に設定します。これで、A1セルを起点にタイトル行が転記されます。
表の転記
次に、表の内容を転記します。
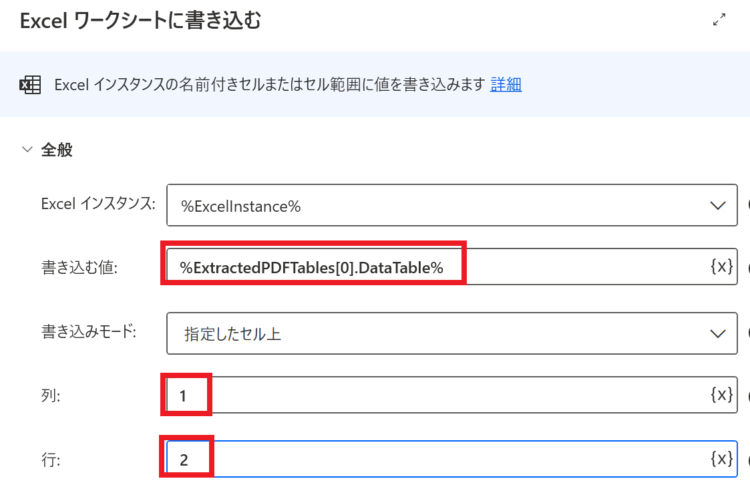
書き込む値に、
%ExtractedPDFTables[0].DataTable%を設定します。2行目から転記したいので、列:1、行:2を設定します。
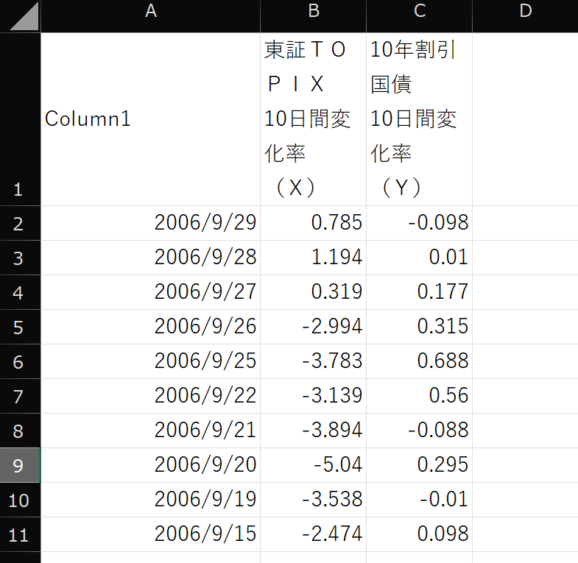
このフローを実行すると、以下のようにPDFから取得したテーブルがExcelに転記されます。
まとめ
今回は、Power Automate Desktop(PAD)の、「PDFからテーブルを抽出する」アクションの使い方について解説しました。
なお、PDFファイルからテキストを取り出す方法については以下記事にて解説しています。

当ブログでは、Power Automate、Power Automate Desktopに関する記事を他にも投稿しています。もし、「このようなことが知りたい」「こんなフローの作り方が知りたい」等ございましたら、問い合わせやコメントからお気軽にご連絡ください。



コメント