
今回は、Power Automate Desktop(PAD)で、複数ページをスクレイピングする方法・テーブル構造になっているWebページをスクレイピングする方法について解説します。
なお、本記事はPADの基本的な操作は理解している方を対象としています。表題のとおり、複数ページに渡る複数のデータ、テーブルのデータをスクレイピングする、という方法をピンポイントで解説していきます。
はじめに
本記事でスクレイピング対象とするサイトは、マイナビ転職とします(理由は特にないです)。
検索条件を入れて検索すると、検索結果が一覧で表示されます。
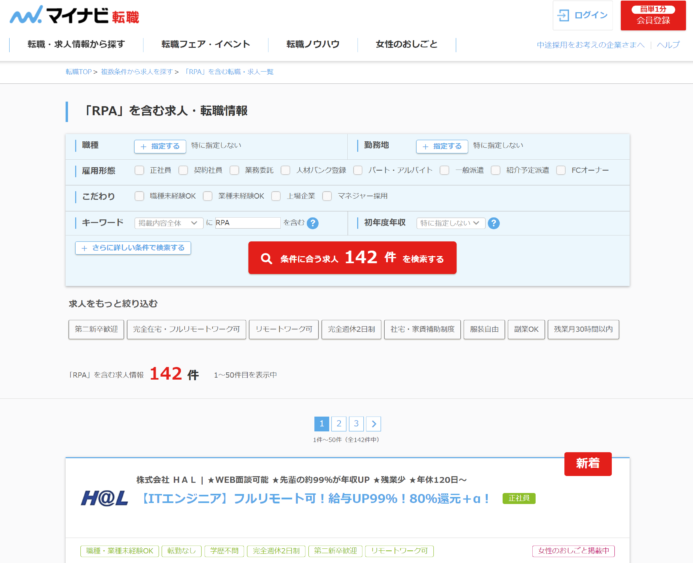
検索結果は複数ページにわたる場合もあり、ページングされています。

このようなページに対して、1件ずつ募集内容をスクレイピングして、Excel(csvファイル)で一覧化する、というのが本記事で行う操作です。
【事前準備】Webページを開く・検索する
スクレイピングする事前準備として、以下の操作をフローに追加しておきます。
- ブラウザを起動する
- 検索条件などがあれば入力・選択する
- 検索ボタンを押す
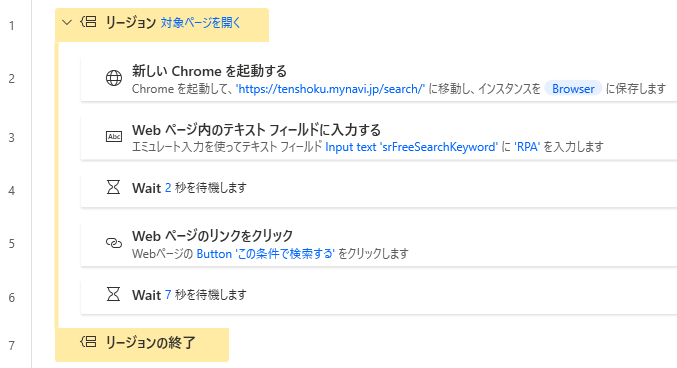
今回の例であれば、マイナビ転職の検索ページを開き、テキストボックスに「RPA」と入力して、「検索」ボタンを押すまでの流れです。
上記のフロー内では「リージョン」という黄色く囲んだブロックのようなものを作っていますが、これは必ずしも作る必要はありません。
ただ、フローが長くなってきたときにリージョンごとに折りたためたりするので、けっこう便利でおすすめの機能です。
アクション:「Web ページからデータを抽出する」
Web ページからデータを抽出する
このアクションをフローに追加すると、以下のようなダイアログが開きます。
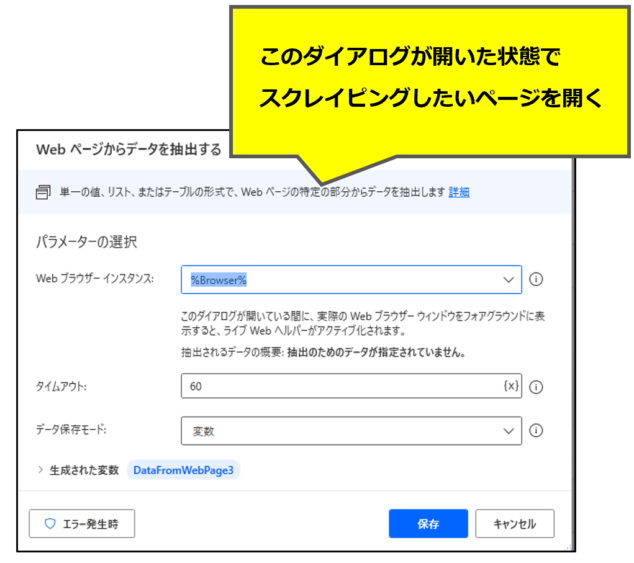
ダイアログが出た状態でスクレイピングしたいページを開く
このダイアログが開いた状態で、スクレイピングしたいページを開きます。今回であれば検索結果一覧のページです。
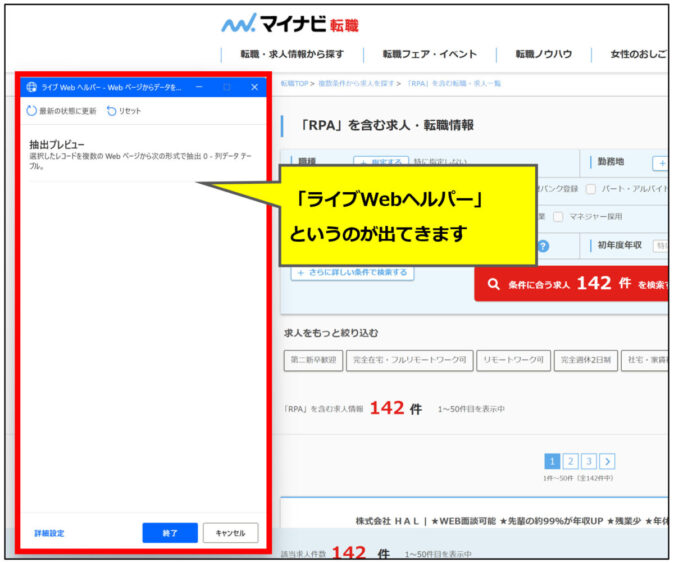
スクレイピングしたいページを開くと、「ライブWebヘルパー」というダイアログが出てきます。
ライブWebヘルパーの設定
「ライブWebヘルパー」が出ている状態でページを開くと、各HTML要素にカーソルをあてるごとに赤枠が表示されます。
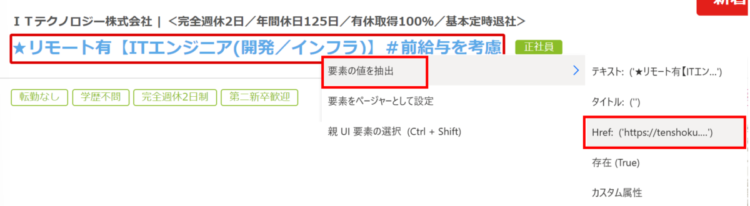
まず、検索結果一覧から各ページのタイトルを取得します。タイトル部分にカーソルを当てると赤枠が表示されますので、右クリック>「要素の値を抽出」を押します。
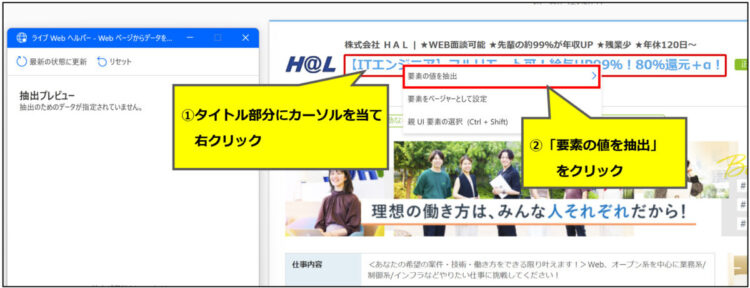
続けて、「テキスト:~~~~」を選択します。
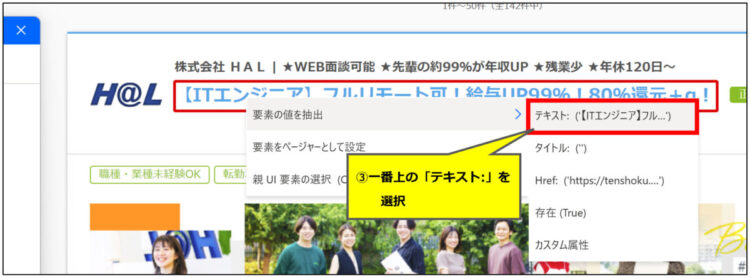
すると、選択したテキストが「ライブWebヘルパー」に追加されました。
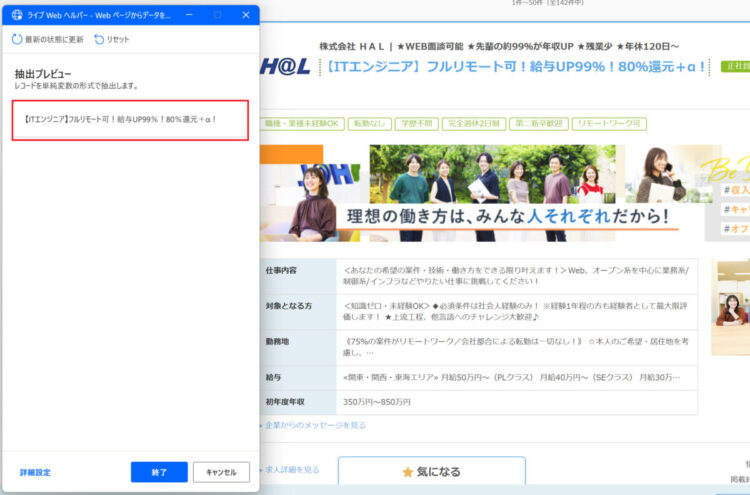
これじゃ固定の値しか取れない(ページの中身が変わったらだめ)なんじゃないの!?
ここで、「この設定方法だと、選択したタイトルがセットされてるし、ページの内容がもし変わったら取れないんじゃないの!?」と思う方もいらっしゃるかと思います。
私自身、このアクションを最初に使おうと思ったときに、「固定で設定していくなら、中身変わったら値取れないじゃん。やっぱPADでスクレイピングは無理か・・・」とあきらめかけました。
でも、安心してください。このまま手順を進めていくと、検索結果の内容が変わっても問題なくスクレイピングできるフローが完成します。
2件目を設定すると、以降のデータが自動で設定される!
先ほどと同じように、2件目のデータも「ライブWebヘルパー」に追加します。
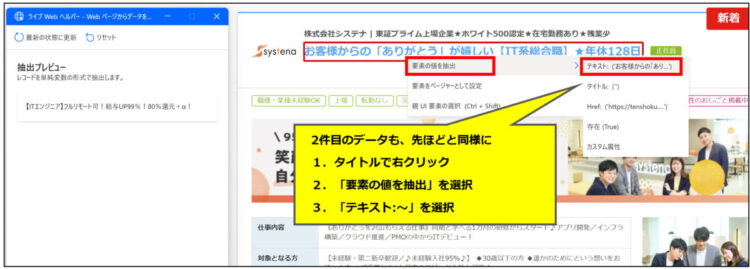
すると、3件目以降のデータもブワッと一気に設定されます。
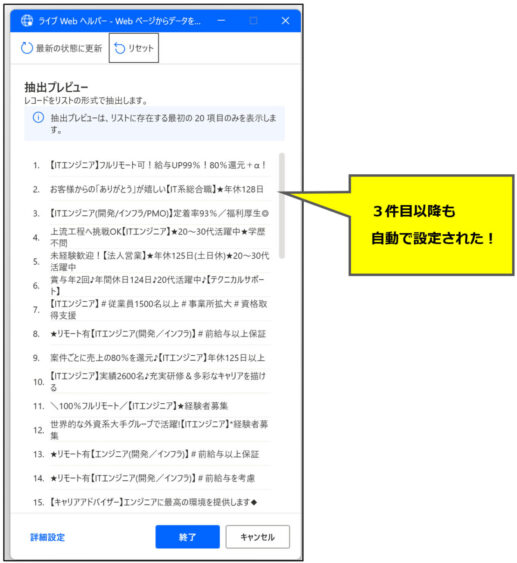
タイトルが固定で取れてるような感じがしますが、これで大丈夫です。検索結果の内容が変わっても、問題なくスクレイピングできます。
続けてページャーの設定をしますので、「ライブWebヘルパー」は開いたままにしておいてください。
ページャーの設定
ページが複数ある場合に、複数ページが取得できるようページャーの設定をします。
ページャーにカーソルをあてて右クリック>「要素をページャーとして設定」を押します。
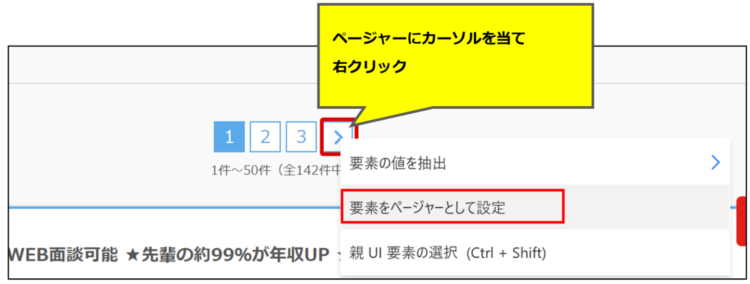
押しても何にも反応がないのですが、設定はできています。
「ライブWebヘルパー」の「終了」を押下してPADのフローに戻ります。すると、アクション追加時には表示されていなかった「処理するWebページの最大数」という項目が表示されています。
ここに、何ページまでスクレイピングするかを設定します。
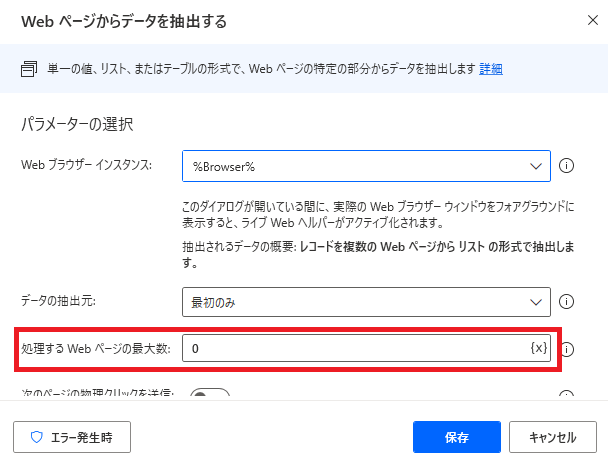
ここまでで、検索結果一覧を抽出する操作は完了です。
Excelに検索結果を転記する
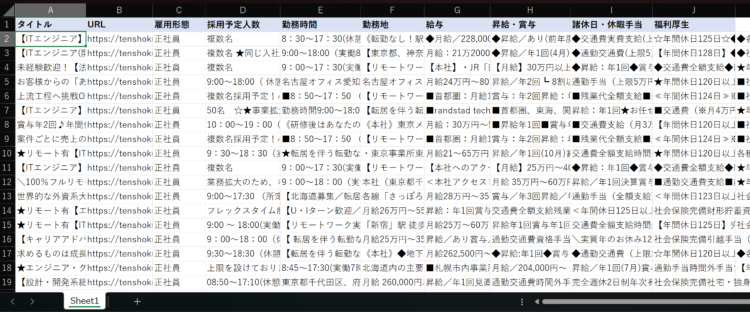
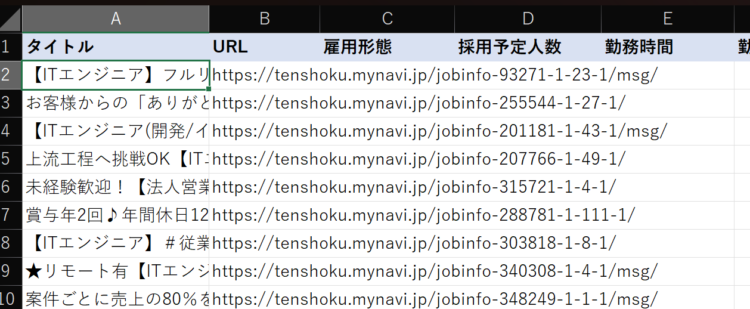
ここまでのフローを動かしてみると、「Webページからデータを抽出する」アクションで取得した内容は以下のようになっています。タイトルと、タイトルのリンクがデータテーブルとして変数に格納されています。

この内容を、Excelに転記します。
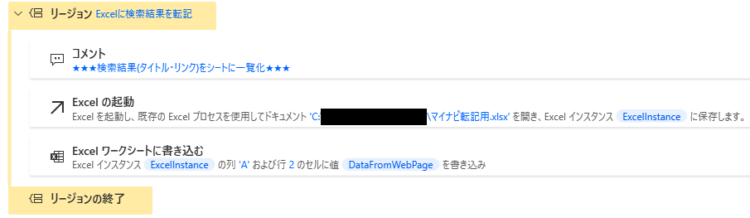
データテーブルはそのまま一気にExcelにベタっと貼り付けられるので、「Excelワークシートに書き込む」アクションを使って変数を書き込み対象に設定します。
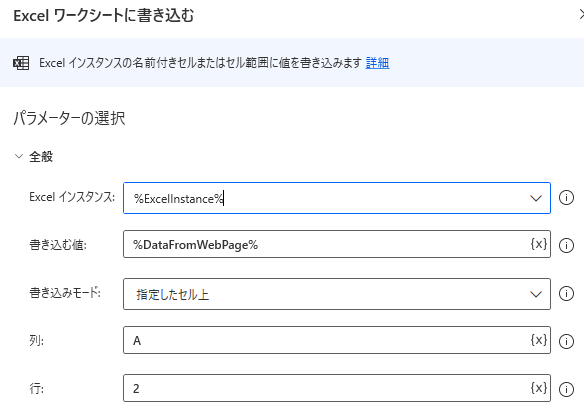
書き込み開始位置はべた書きしてますが、空白行から追加していきたい場合には「Excelワークシートから最初の空の列や行を取得」というアクションを使うと実現可能です。
これでフローを実行すると、ExcelのA2セルを先頭に、データテーブル変数に入っている内容が貼り付けされます。
テーブルのスクレイピング
ここまでで、検索結果一覧の各ページのタイトル・URLを取得することができました。
続いて、各ページの中身を取得していきたいと思います。
取得したデータテーブルをFor eachで順に処理する
先ほど取得した一覧は、DataFromWebPageというデータテーブル変数に格納されています。これをFor eachで一つずつ見ていきます。
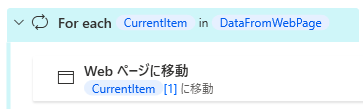
For eachでデータテーブルから1行ずつ取り出されるので、CurrentItem[1]にはURLが入っています。「Webページに移動」アクションを使うと、指定されたページが開きます。

ここまでの手順でリンク一覧が取れていない場合は、アクション:「Web ページからデータを抽出する」の設定で、要素の値を抽出>Href を選択してください。Hrefでは各ページのリンク一覧のみが取得できます。
テーブルのスクレイピング
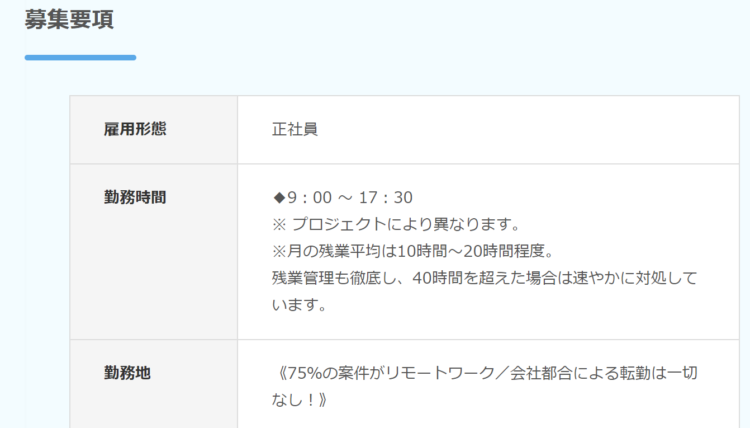
開いたページから、以下のようなテーブル部分のみ取得します。
今回も「Webページからデータを抽出する」アクションを使います。
開いたページ上の、テーブルになっているところにカーソルをあて、右クリックして「HTMLテーブル全体を抽出する」を選択します。

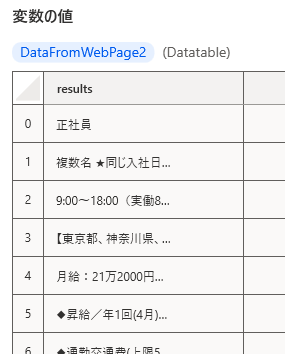
テーブルの中身は、DataFromWebPage2という変数に格納されます。
実際の変数の中身は以下のようになっています。
これを、先ほどのExcelに転記していってあげると表が完成します。

スクレイピングに失敗する場合
スクレイピング時に、以下のエラーが出ることがあります。
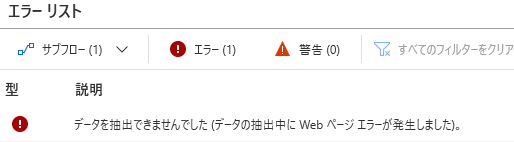
データを抽出できませんでしたこちらのエラーは、エラーメッセージ通り、スクレイピングができなかったというエラーなのですが、原因としては
- テーブルをスクレイピングするようにしているが、該当ページにテーブルがない
- 複数あるページのうち、一部だけページのつくりが違う
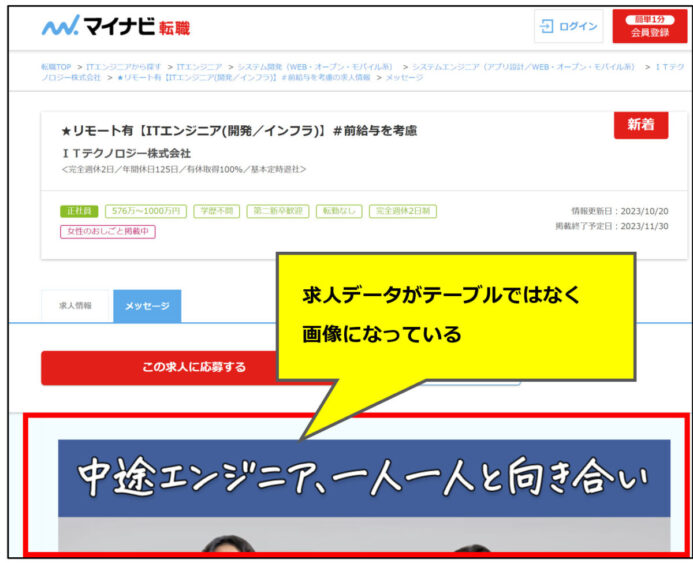
といった場合に発生します。例えば今回の例では、検索結果を1ページずつ中身を見てテーブルの部分をスクレイピングしていますが、まれにテーブルがなく画像のみの求人情報になっている場合があり、このようなエラーが発生していました。
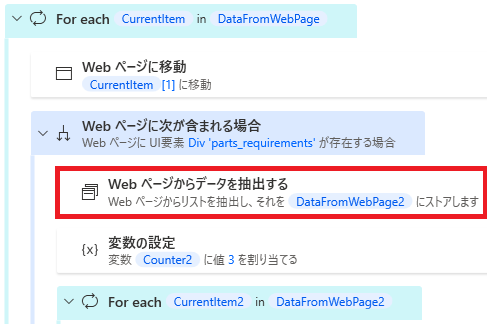
解決策としては、「Webページに次が含まれる場合」アクションを用いて、スクレイピングする対象があるかどうか確認してからスクレイピングするようにします。
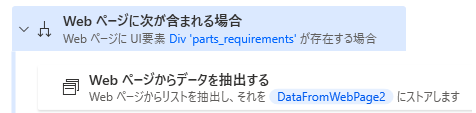
これで、テーブルがあるかどうかチェックして、あるときだけスクレイピングするようになるのでエラーを回避できます。
まとめ
今回は、Power Automate Desktop(PAD)で、複数ページをスクレイピングする方法・テーブル構造になっているWebページをスクレイピングする方法について解説しました。
私自身、仕事でPADを用いてスクレイピングする機会があり、色々と苦戦しつつも分かったことを記事にまとめてみました。スクレイピング関連のアクション、ちょっと分かりづらいな・・・と感じました。特に「ライブWebヘルパー」とかいう無駄に名前だけかっこいいやつ、使いこなすまでにだいぶ悩みました。
もし、本記事のなかで分からないことや、「こんな処理を実現したいんだけど、どうやるの?」といった質問などがありましたら、お気軽にコメントいただければと思います。問い合わせフォームからご連絡いただいてもかまいません。
本記事が少しでもお役に立てればうれしいです。


コメント