
今回は、Seleniumでテーブルの要素を取得する方法について解説します。
基本となるソースコード(これをベースに解説します)
本記事のサンプルコードは、全て以下のコードをベースに解説しています。
from selenium import webdriver
#import chromedriver_binary # chromedriver-binaryの場合これも必要
import time
from selenium.webdriver.common.by import By
# 指定したページを開く
driver = webdriver.Chrome()
driver.get('https://www.yahoo.co.jp/')
# ページが開くまで待機
time.sleep(3)
# ▼本記事のサンプルコードはここに記載しています
# ▲本記事のサンプルコードはここに記載しています
# ウインドウを閉じる
driver.close()指定したページ(サンプルではYahoo!JAPANのトップページ)を開いて、3秒後に閉じるというコードです。各解説では、上記内容は省略していますが、ご自身の環境で動かす場合はsleepメソッドのあとに追加するようにしてください。
HTMLのテーブル要素について
テーブルとは、データ行と列の組み合わせから成る表形式のデータです。
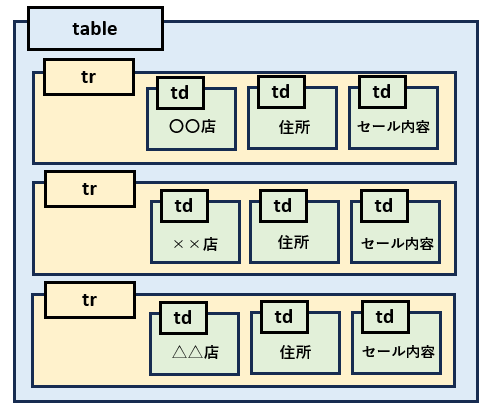
テーブルを構成するタグ
テーブルを構成するタグは以下になります。実際のページではthタグがない場合もけっこうあります。
| タグ名称 | 概要 |
|---|---|
| tableタグ | テーブル全体 |
| thタグ (table header) | 見出しセル (ないことも多い) |
| trタグ (table row) | テーブルの行 |
| tdタグ (table data) | テーブルのデータ |
テーブル要素の基本的な取得手順
テーブルの要素を取得する方法は以下のとおりです。
- 親要素を取得する (find_element)
- 取得した親要素から子要素のリストを取得する (find_elements)
- 取得したリストから対象のものを取り出す
「1.親要素を取得する」は、対象のWebページにテーブルが一つだけしかない場合は不要です。
テーブルが複数ある場合は、テーブルの中身(trタグ、tdタグ)で要素を取得しようとすると全てのテーブルの中身が取れてしまうので上記のステップが必要です。
今回使用するテーブル
今回は、以下のテーブルを例にして解説します。
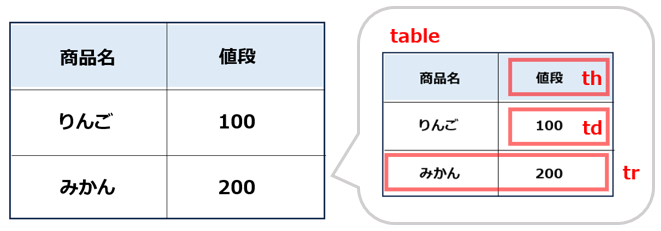
<table>
<tr>
<th>商品名</th> <th>値段</th>
</tr>
<tr>
<td>りんご</td> <td>100</td>
</tr>
<tr>
<td>みかん</td> <td>200</td>
</tr>
</table>tdのみを取得したい場合
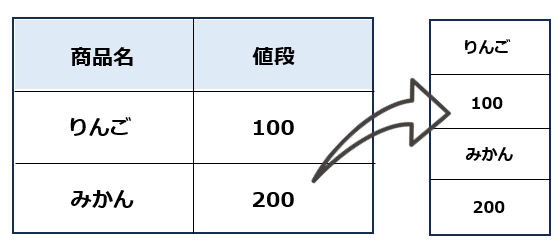
テーブルから、「りんご 100 みかん 200」のみ取り出す場合は以下のようになります。
# 対象のテーブルを取得
element = driver.find_element(By.XPATH, '/html/body/table[1]')
# 取得したテーブルからtdタグの中身をリストで取得
tdlist = element.find_elements(By.TAG_NAME, 'td')
# リストの中身をログに出力
for elem in tdlist:
print(elem.text)# 実行結果
りんご
100
みかん
200サンプルでは、テーブルにname属性がないため、XPathを用いてテーブルの要素を取得しています。もし、<table name=’table1′>のようにname属性が設定されている場合は、
# 対象のテーブルを取得
element = driver.find_element(By.NAME, 'table1')と指定することも可能です。
thも含めて取得したい場合
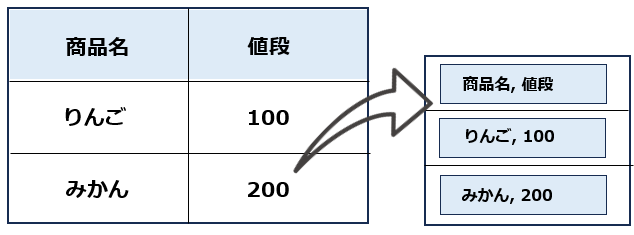
th(テーブルヘッダ)も含めて取得したい場合は、以下のようになります。
# 対象のテーブルを取得
element = driver.find_element(By.XPATH, '/html/body/table[1]')
# 取得したテーブルからtrタグの中身をリストで取得
trlist = element.find_elements(By.TAG_NAME, 'tr')
# リストの中身をログに出力
for elem in trlist:
print(elem.text)# 実行結果
商品名 値段
りんご 100
みかん 200trを指定することにより、テーブルの各行がリストで取得できます。1レコードを一つのグループとして扱いたい場合はtrタグで指定すると良いでしょう。
特定の列だけ取得したい場合
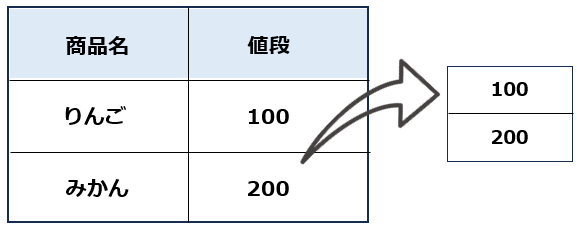
特定の列だけを取得したい場合、以下のように行います。
# テーブルの特定の列をリストで取得
elements = driver.find_elements(By.XPATH, '/html/body/table[1]/tbody/tr/td[2]')
# リストの中身をログ出力
for elem in elements:
print(elem.text)
# 実行結果
100
200テーブル列の指定方法
テーブルの列を指定する場合にはXPathを使います。取得したい列の要素のXPathを調べると、
/html/body/table[1]/tbody/tr[2]/td[2]上記のように、「tbody/tr[2]/td[2]」という並びになっている箇所があるかと思います。これを、
/html/body/table[1]/tbody/tr/td[2]trのインデックスを指定しないことで、指定した列の要素すべてが取得できるようになります。
特定の行だけ取得したい場合
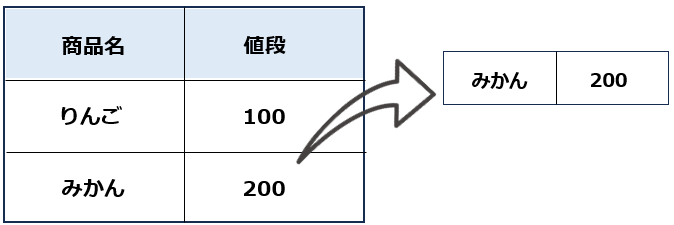
特定の行だけを取得したい場合、以下のように行います。
# テーブルの特定の列をリストで取得
elements = driver.find_elements(By.XPATH, '/html/body/table[1]/tbody/tr[3]/td')
# リストの中身をログ出力
for elem in elements:
print(elem.text)# 実行結果
みかん
200テーブル行の指定方法
テーブル列の指定と同様、XPathを使います。取得したい行の要素のXPathは以下のようになっています。
/html/body/table[1]/tbody/tr[3]/td[1]「tbody/tr[3]/td[1]」という並びになっている箇所を、
/html/body/table[1]/tbody/tr[3]/tdtdのインデックスを指定しないことによって、指定した行の要素全てが取得できます。
条件に一致するレコードだけ取得したい場合
スクレイピング等では、条件に一致するデータだけを取得したい場合があるかと思います。
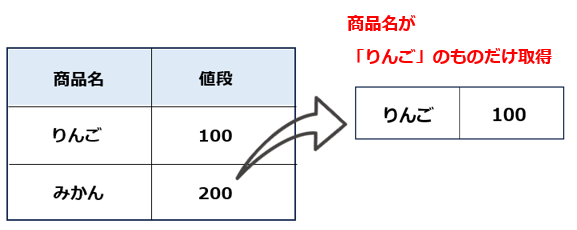
# 対象のテーブルを取得
element = driver.find_element(By.XPATH, '/html/body/table[1]')
# 取得したテーブルからtrタグの中身をリストで取得
trlist = element.find_elements(By.TAG_NAME, 'tr')
# リストの中身に特定の文字が含まれていたらログ出力
for elem in trlist:
if 'みかん' in elem.text:
print('データが見つかったよ')trタグでテーブルを1行ずつリストで取得し、そのリストをループで回して特定の文字が含まれているかチェックしています。完全一致で検索したい場合はinを「==」に変更してください。
- A == B :AとBが等しい(完全一致)
- A in B : Aという文字列がBに含まれる(部分一致)
条件に一致するデータだけ取り出して新たなリストに格納するには以下のように行います。
# 対象のテーブルを取得
element = driver.find_element(By.XPATH, '/html/body/table[1]')
# 取得したテーブルからtrタグの中身をリストで取得
trlist = element.find_elements(By.TAG_NAME, 'tr')
# 条件に一致したデータを入れるリスト
fruits_list = []
# リストの中身に特定の文字が含まれていたらfruits_listに追加
for i,elem in enumerate(trlist):
if 'みかん' in elem.text:
fruits_list.append(elem.text) # 新しいリストに追加
print(fruits_list)# 実行結果
['みかん 200']テーブルの中にテーブルがある場合

テーブルの中にテーブルが入れ子になっている場合は、以下の手順で取得します。
- 親テーブルを取得
- 親テーブルから子テーブルの要素を取得
# 親テーブル(外側のテーブル)を取得
element = driver.find_element(By.XPATH, '/html/body/table[2]')
# 親テーブルから対象のテーブルを指定して要素を取得
trlist = element.find_elements(By.TAG_NAME, 'tr')
# 取得したテーブルの中身をログ出力
for el in trlist:
print(el.text)
# 実行結果
トマト 300
にんじん 150親テーブルを取得したあとは、これまでに説明したテーブルの取得方法の通りに行うだけです。入れ子になっている場合の子要素の取得方法について、詳しくは以下の記事で説明しています。

うまく取得できない場合
上記手順で要素がうまく取得できない場合、スペルミスのような軽微なミスから、要素がjavascriptになっている、iframeの中になるなど様々な原因が考えられます。
以下記事にて、要素の取得に失敗した場合の対処法を解説していますので、あわせてご確認ください。

まとめ
今回は、Seleniumででテーブルの要素を取得する方法について解説しました。
スクレイピングを行う場合、テーブルのデータを扱う機会がけっこう多いです。テーブルの構成はページによって様々ですが、基本的な取得方法をマスターしておけば応用できると思います。
今回の記事が参考になれば幸いです。



コメント