
画像生成AIであるStable Diffusion Web UI(AUTOMATIC1111)についての基本機能であるtxt2img(text to image)について設定項目と内容を画像付きで詳しく解説します。
- はじめに
- Stable Diffusionとは
- Stable Diffusion Web UI(AUTOMATIC1111)とは
- AUTOMATIC1111の初期画面の解説と簡単な使い方
- txt2img(text to image)の項目と詳細内容解説
- Generation
- まとめ
はじめに
この記事では、ローカルPC(自身のパソコン)でStable Diffusionを簡単に扱うことのできるWeb UI(AUTOMATIC1111)について、基本的な機能であるtxt2img(text to image)について設定項目と内容を画像付きで詳しく解説します。
Stable Diffusionとは
Stable Diffusionとはディープラーニング技術を用いて作られたtext-2-imageモデル(テキストを入力すると画像が出力されるもの)です。
text-2-image以外にも、インペインティング(Inpainting:画像の一部領域の損傷・劣化・欠落部分を(違和感なく)補正する)、アウトペインディング(Outpainting:元画像の領域の外側を補正する)、image-2-image(コマンドではなく画像を入力し、そこから新たな画像を生成する)ことができます。
Stable Diffusionの詳細とインストール方法などについては、以下の記事にまとめています。

Stable Diffusion Web UI(AUTOMATIC1111)とは
Stable Diffusion Web UIとは、Stable DiffusionをWebブラウザで簡単に扱うためのソフトウェアの一種です。
AUTOMATIC1111はWeb UIの中でも最も有名なソフトの1つといっても過言ではありません。
AUTOMATIC1111のインストール方法などは以下の記事にまとめています。
AUTOMATIC1111の初期画面の解説と簡単な使い方
実際にStable Diffusion Web UI(AUTOMATIC1111)の初期画面の解説と簡単な使い方は以下の記事にまとめています。

txt2img(text to image)の項目と詳細内容解説
ここでは、Stable Diffusion Web UI(AUTOMATIC1111)の中で基本機能となるtxt2img(text to image)について、設定画面と内容に関する詳しい説明を行っています。
txt2img(text to image)での設定画面詳細は以下のようになっています。
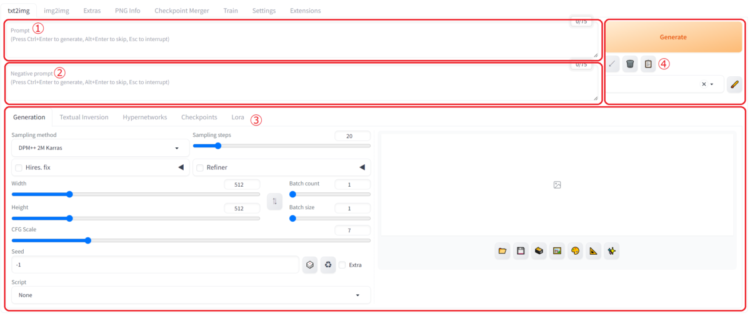
①プロンプト(テキスト)入力エリア
作りたい画像の内容をここに記載します。英語で入力します。75単語まで入力することができます。
作りたい画像を思い通りにするにはプロンプト入力(と後述のネガティブプロンプト)が肝です。
②ネガティブプロンプト入力エリア
ネガティブプロンプトとは画像生成の上で「描画させたくない」ことを記述する場所です。
こちらも英語で75単語まで指定することができます。
③txt2imgでの詳細設定エリア
ここでtxt2imgでの詳細な設定を行うことができます。以降は詳細設定エリアについて細かく見ていきます。
Generation
一般的な設定を行うことができます。
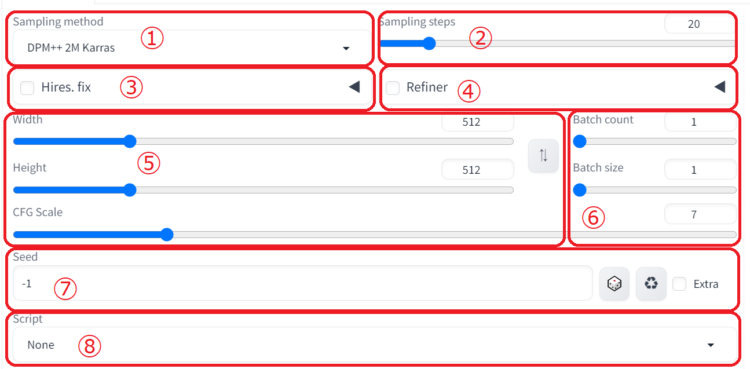
①Sampling method
サンプラー(sampler)とも言います。画像生成AIでは、画像生成する際にノイズが混じっている画像を作っています。ノイズを取り除くための様々なアルゴリズム(手法)があり、Stable Diffusionはそれを指定することができます。ver1.8.0の時点でも以下のように大量に存在します。

Sampling methodはアルゴリズムや後述するSampling stepsの数が少なくても良い画像が得られたり、生成するまでの時間を短縮したりすることができる場合があります。また生成したい画像の好みによって利用するものが変えるとよいものができたりし、かなり奥が深いです。
よく使われているものとして挙げられるのは、以下のアルゴリズムのようです。
- DPM++ SDE Kerras
- DPM++ 2M Kerras
- Euler a
結局のところ、同じプロンプトでアルゴリズムを複数試してみてどのようになるかを確認し、自分が目指す画像に一番近いものを採用する必要がありそうです。
②Sampling steps
上記①でノイズを除去する話をしていますが、それを何回行うか指定します。
Stable Diffusionの初期設定値は20になっています。そのままでも十分な画像を生成することが可能ですが、例えばアニメ調の画像がいいのか写真のような画像が良いのかによってstep数を変更したほうがいい時もあります(写真のようにしたいときは回数を増やしたり)。
また、アルゴリズムによってはstep数を増やすと中身がガラッと変わることがあります。
ここも試行錯誤が必要なものになります。
③Hires. fix
Stable Diffusionはcheckpoint(AIモデル)ごとに得意とする画像サイズが存在します(512×512など)。このサイズを超えたサイズの画像を作ろうとした場合、急に構図が崩れ、変な画像(破綻した画像)を出力されることがあります。これを抑えるための機能がHires. fixです。
A convenience option to partially render your image at a lower resolution, upscale it, and then add details at a high resolution. In other words, this is equivalent to generating an image in txt2img, upscaling it via a method of your choice, and running a second pass on the now upscaled image in img2img to further refine the upscale and create the final result.
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#hires-fixより抜粋
引用した概要からでは、得意とするサイズで画像データをいったん作成したのち(第一段階)、画像データをアップスケール(画像を元のサイズより大きな画像にする)します。アップスケールした画像を用いてさらに詳細な画像を作ります(第二段階)。つまり2段階目はimage 2 image(画像から画像を作っている)を行っているようです。
右側の逆再生ボタンのようなものを押すと、詳細設定ができるようになります。

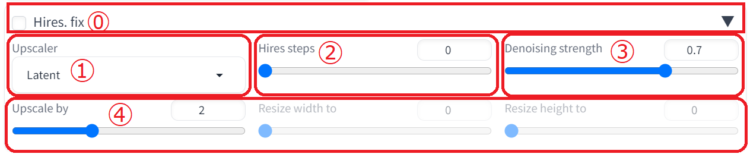
⓪設定状態の反映
Hires.fixの左側のチェックボックスにチェックを入れることでこの項目がONになります。
またチェックを入れると、元の画像がどの大きさまでアップスケールされるのかサイズが記載されます(画像の場合、以降の設定で、2倍になるような設定になっている)。

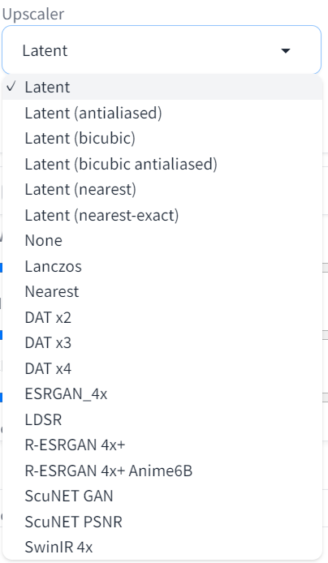
①Upscaler
前述の説明中の第一段階から第二段階にアップスケールする際に利用するアルゴリズムを指定します。
こちらもver1.8.0の時点で大量にあります。特段こだわりがなければ最初から選択されているLatentで十分だと思います。
②Hire steps
前述の説明中の第二段階を何回行うかを指定します。大体10~20くらい行えば十分のようですが、Upscalerによってはもっと少なくても良い精度で出るようです。
また0回を指定すると、Sampling stepsと同じ回数行われます。注意しましょう。
③Denoising strength
前述の説明中の第一段階で作成された画像に対してどのくらい再現するかを示します。
0に近づくほど、第一段階の画像を忠実に再現しようとします。また、画像がぼやける傾向にあります。1に近づくほどぼやける感じは解消されますが、第一段階の画像から乖離していきます。
④Upscale by / Resize width to ・ Resize height to
Upscale byは元の画像を何倍にするか指定することができます。
0.05倍単位で大きくすることができます。大きくしすぎると、描画に時間がかかります(例えば全体を2倍にすると、高さ2倍、幅2倍で面積は4倍になるので)。
Resize width toとResize height toは0のままでは色がグレーで無効化されています。

0以外を指定すると黒くになり有効になります。反対にUpscale byはグレーとなり無効化されます。

④Refiner
Refinerはver1.6.0から追加されている比較的新しい機能です。
画像は基本的に1つのcheckpoint(AIモデル)が最初から最後まで画像を生成していましたが、このRefinerを使うことで、途中までは初めのcheckpointで画像を作成し、途中から最後まで指定された別のcheckpoint(AIモデル)を用いて画像を生成していきます。
右側の逆再生ボタンのようなものを押すと、詳細設定ができるようになります。


⓪設定状態の反映
Refinerの左側のチェックボックスにチェックを入れることでこの項目がONになります。
チェックを入れても、Hires. fixのように何か情報が表示されるわけでないのに注意が必要です。

①Checkpoint
途中から切り替えたいcheckpoint(AIモデル)を指定します。checkpoint(AIモデル)選択後に右側のアップデートボタンのようなものを押さないと反映されませんので注意してください。

ボタンを押すと、データをロードするフローが出るので、終わるまで待ちましょう(数秒で終わりますが)。

②Switch at
画像生成で画像が出来上がるまでを1としたとき、いつ最初のcheckpoint(AIモデル)からRefinerのcheckpoint(AIモデル)に切り替えるかを指定することができます。
0.01(1%)~1(100%、つまりRefinerのcheckpointを使わない)まで指定できます。小さければ小さいほど、Refinerで指定したcheckpoint(AIモデル)を適用します。

⑤画像サイズとプロンプト再現度の設定
ここでは画像サイズ設定とプロンプト再現度を設定することができます。
①WidthとHeight
横のサイズと縦のサイズを決定します。デフォルトではどちらも512(ピクセル)です。

右側にある上下矢印をクリックすることでWidthとHeightの数値を入れ替えることができます。

②CFG Scale
入力するプロンプトに対してどれだけ忠実な画像を作成するか数値を用いて指定します。数値大きく設定するとプロンプトに対して忠実に再現しようとしますが、忠実に再現しようとするあまり、画像が崩れやすくなります。一方で数値を小さく設定するとプロンプトに対しての再現度は低くなりますが、画像の品質は上がります。通常は7-11の間を設定します。

⑥生成する画像枚数の設定
ここでは一度に生成する画像枚数を指定することができます。
①Batch count
連続で生成する画像枚数を指定します。最大100まで設定可能なため、一度に100枚まで生成することができます。
②Batch size
Batch countで指定した数値の指定倍数分の画像を生成することができます。最大で8まで指定することができます。基本的には、Batch countの上限である100枚より多くの画像を生成したいときに使用するとよいです。
ただし、3以上にすると、画像生成時にエラーなどで止まりやすくなります。できれば2までにして、Batch count側で枚数を調整する方向がよいでしょう。

⑦Seed
生成されている画像は大きく「プロンプト」と「Seed」の2つの値に基づいて人物(キャラクタ)や構図が形成されています。同じプロンプトで画像を作成しても、Seed値も変わっているため、人物(キャラクタ)や構図が異なる画像が生成されていく仕組みになっています。
人物(キャラクタ)や構図をほぼ同じ条件で何度も画像を変更したときは、元画像に含まれるSeed値と変更したプロンプトを指定することで可能になります。

通常はSeedは-1が指定されています。-1=ランダム値となっていて、画像を生成するたびにSeed値がランダムに出力されます。
自由な数値を入力することでSeed値は変えることができますが、右側のサイコロボタンをクリックすると、-1がセットされます。

直前に生成した画像のSeed値を利用する場合は、サイコロボタンの右側にあるリサイクルマークのようなボタンをクリックすると、直前に生成した画像のSeed値が反映されます。

画面右側のExtraをチェックすると、さらに細かくSeedオプションを開いて調整することができます。
イメージとしては、指定されたSeed値の画像からさらにSeed値を設定し、そのSeed値は元のSeed値にどのくらい似ているものにするかというものになります。
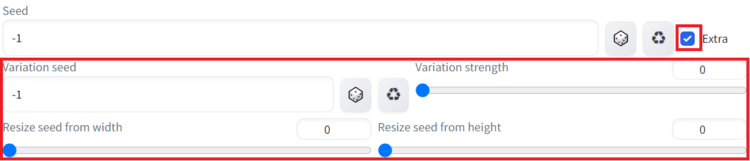
①Variation seed
元のSeed値で生成される画像に対して、さらにVariation seed値を足した画像を生成する場合に使用します。基本的には-1(触らない)で問題ありません。
また、Seedの時と同様にサイコロマークで-1に設定し、リサイクルマークのようなもので直前に生成された画像のVariation seedを取得することができます。
Variation strengthと組み合わせて利用します。

②Variation strength
元のSeed値で生成される画像に対して、新たに足すSeed値(Variation seed)をどのくらい足すか設定します。設定は0~1まで0.01単位で設定することができます。
1に近づくほどVariation strengthの値を足していくので、元のSeed値で生成された画像から離れていきます。
少し変えるくらいであれば、0.2を基準に少しずつ増やしたり減らしたりするとよいでしょう。

③Resize seed from width、Resize seed from height
プロンプトやSeed値が同じでも、画像サイズを変更すると出力される画像の内容も変化します。この設定では、出力される人物(キャラクタ)や構図を極力同じままにして、画像のサイズを変更するために使用します。
0のままであれば元の画像と同じものを出力します。2048×2048サイズまでの範囲で変更することができます。

⑧Script
検証用オプションです。選択できる項目を選択することでいくつかの設定を行うことができます。

①None
何も設定しないときはこの設定です。デフォルトでもこの設定になっています。
②Prompt matrix
プロンプト内で「|」で区切ると、そのプロンプトを「使った場合」と「使わなかった」場合の画像データを出力します。イメージ的には、「|」で指定されたプロンプト1つ1つに対して、プロンプトをONOFFして、全組み合わせを出力するというイメージです。デフォルトの設定では、以下のように入力します。
外せないプロンプト1,外せないプロンプト2,( ... ,)|有無検証したいプロンプト1|有無検証したいプロンプト2(|...)外せないプロンプトのあとは「,」のあとに「|」が必要で、検証したいプロンプトの羅列では「,」は不要で「|」のみで区切ります。上記のプロンプトでは以下のプロンプトを指定した時と同じ画像が出力されるようになります。
外せないプロンプト1,外せないプロンプト2外せないプロンプト1,外せないプロンプト2,有無検証したいプロンプト1外せないプロンプト1,外せないプロンプト2,有無検証したいプロンプト2外せないプロンプト1,外せないプロンプト2,有無検証したいプロンプト1,有無検証したいプロンプト2便利に使うことができますが、組み合わせは「2^有無検証したいプロンプト数」になるので、一気に全部|で区切らず、少しずつ進めるようにしましょう。
Prompt matrixを選択すると、設定項目が増えます。
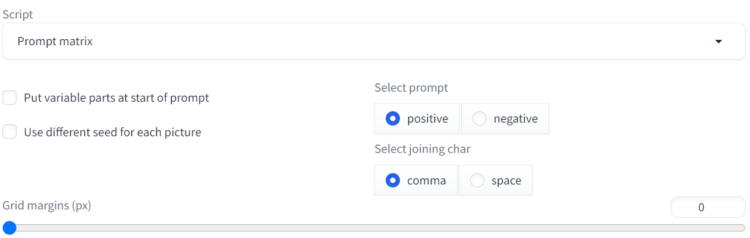
①Put variable parts at start of prompt
上記の例題では必要なプロンプトを並べたあと、検証用プロンプトを並べています。チェックを入れると順番が逆になり、検証したいプロンプトを前面にしてから処理を行います。Stable Diffusionではプロンプトが前にあるほど強い条件として作用するので、先に検証したいものを持ってくると影響が強くなります。

②Use different seed for each picture
上記の例題では必要なプロンプトを並べたあと、検証用プロンプトを並べています。チェックを入れると順番が逆になり、検証したいプロンプトを前面にしてから処理を行います。Stable Diffusionではプロンプトが前にあるほど強い条件として作用するので、先に検証したいものを持ってくると影響が強くなります。

③Select prompt
画像そのものには影響しない設定項目です。Prompt matrixの設定をポジティブプロンプト、ネガティブプロンプトどちらに適用するか指定します。
④Select joining char
画像データが出力された際、プロンプトが記録されています。「|」で囲った部分のプロンプト部分を「,」で区切って出力するか「 (スペース)」で出力するか決めます。
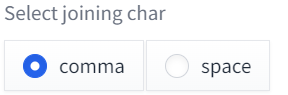
プロンプトA,プロンプトB,|プロンプトC|プロンプトD上記のプロンプトに対して、全プロンプトが出力された画像の場合、commaの場合とspaceの違いは以下のようになります。
comma
プロンプトA,プロンプトB,プロンプトC,プロンプトDspace
プロンプトA,プロンプトB,プロンプトC プロンプトD⑤Grid margins(px)
画像そのものには影響しない設定項目です。結果出力時、画像が複数枚生成されます。その際の各画像同士の間隔をどのくらいにするか決めることができます。0~500まで設定することができます。

③Prompts from file or textbox
元のプロンプトに対して、さらに複数のプロンプトを追加して実行する際に使います。Web UI上に記述するかあらかじめテキストなどに記述しておきそれらを読み込むことができます。
Prompt matrixは元プロンプト×お試しプロンプトを複数組合せる方式ですが、Prompts from file or textboxはプロンプトを組合せではなく、個別(1行ごとに)に設定して実行します。
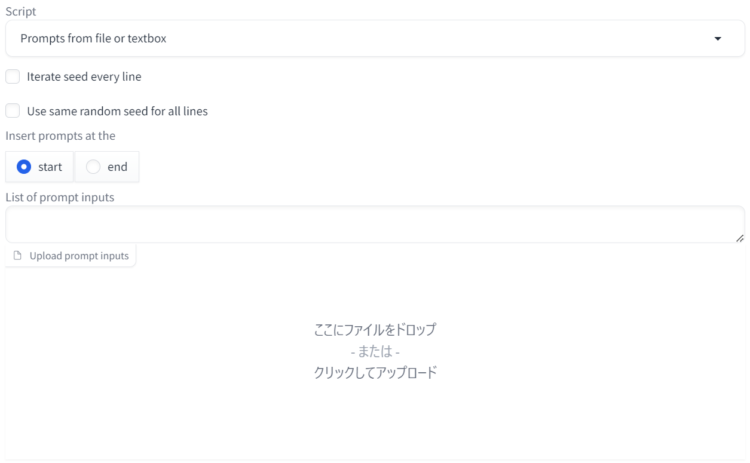
①Iterate seed every line
通常、プロンプト実行時のSeed値はランダムですが、画像ごとに連続したSeed値を設定したい場合は、この項目にチェックを入れます。

②Use same random seed for all lines
すべての画像で同じSeed値を指定したい場合はチェックを入れます。デフォルトではランダム値ですが、Seed設定エリアで指定したSeed値を選択すると、そのSeed値が使用されます。

③Lists of prompt inputs
元のプロンプトに対して、追加するプロンプトを直接各場合はここに書きます。
1行ごとに元のプロンプトと組合せて実行されます。

元プロンプトを以下とします。
元プロンプトA,元プロンプトBテキスト欄に以下のようにデータを入力します。
プロンプトC
プロンプトD,プロンプトE
プロンプトE,プロンプトF上記の場合は、以下のようにプロンプトが実行されます(Insert prompts at the endの場合)。
元プロンプトA,元プロンプトB,プロンプトC
元プロンプトA,元プロンプトB,プロンプトD,プロンプトE
元プロンプトA,元プロンプトB,プロンプトE,プロンプトF④Upload prompt inputs
事前にプロンプトを入力したテキストファイルなどをアップロードできます。1行ごとに1プロンプトとなるようにしましょう。
④X/Y/Z plot
XYZの各軸ごとに単位(使用するデータ)を指定しておき、各軸ごとに値の変化に対する出力画像を比較できるように自動的に並べてくれる機能です。
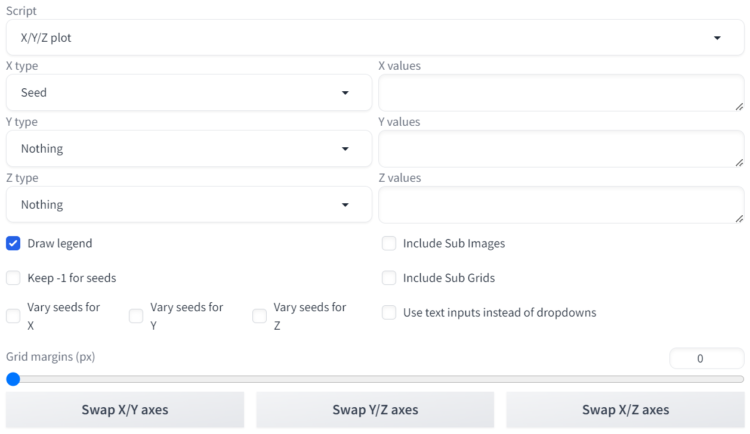
①X type、Y type、Z type
各軸にどのような単位(使用データ)を指定するか決定します。設定できる項目はたくさんありますが、代表的なものとして以下のようなものがあります。
- Nothing:この軸を使用しないときに設定。主にZ軸がメインとなると思います。
- Seed:Seed値を指定
- Var. Seed:Variation Seed値を指定
- Var. Strength:Variation Strength値を指定
- Steps:Steps数を指定
- Sampler:サンプラーを指定
- Checkpoint Name:チェックポイント(モデル)を指定
- VAE:VAEを指定
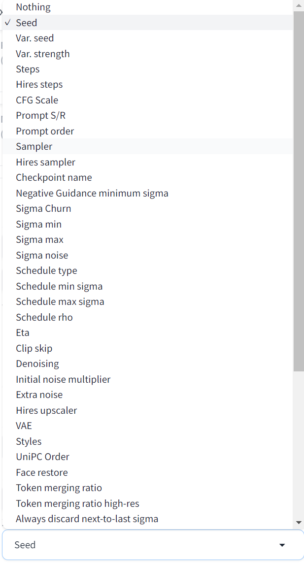
②X values、Y values、Z values
設定した各軸のタイプごとに設定する値を指定します。Stepsのように値を直接記述するタイプの場合は、「,」で値を区切ることにより値を設定することができます。

Samplerなどのようにさらに選択することが可能なものもあります。この場合は選択できるものを指定することができます。複数選択することも可能です。

リスト方式の場合、画面右側にある本のようなアイコンをクリックすると、すべての候補が選択された状態にすることもできます。
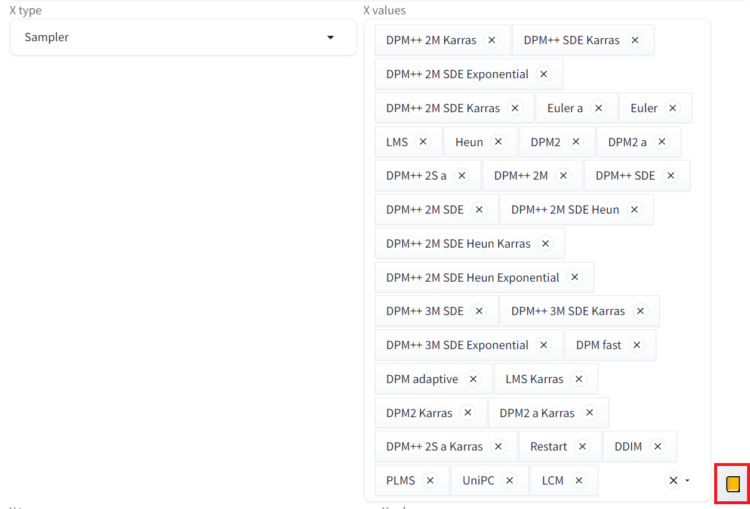
③Draw legend
チェックを入れると、画像を含めた表が表示されます。基本的に設定値の値ごとの絵を見て判断したいはずなので、チェックを入れておきます。デフォルトでもチェックが入っています。

④Keep -1 for seeds
Seed値を固定にするかランダムにするか選択します。基本的にXYZで指定したもの以外は変えたなくないはずなので、OFFにします。
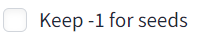
⑤Vary seeds for X Y Z
各軸の値が変わったときに、seed値を変化させるか指定します。チェックした場合はseed値を変化させます。Keep -1 for seedsは、すべて画像のSeed値を変更しますが、ここではチェックしたもの値が変化する場合のみSeed値が変わります。
全部チェックをつけるとKeep -1 for seedsとほぼ同じ意味ですが、設定値がランダムではなく、軸ごとに+1されたSeed値が使用されます。

⑥Include Sub Images
チェックを入れない場合、作成結果に比較マトリクスの画像だけを表示し、それぞれの画像個別のものを作成結果に表示しません。作成した画像をそのまま利用したいときはチェックをつけるようにしましょう。

⑦Include Sub Grids
Z軸まで指定すると、画像は3次元的に表示されるのではなく、Z軸ごとの値ごとにXYの画像が表示されます。XYが2つの値、Zに3つの値を設定しているとXYの画像が3回表示されます。この欄にチェックを入れると、それぞれの3枚の画像を作成結果に表示するか、全体の結果が1枚にまとまっているものだけを作成結果に表示するかを選択することができます。

⑧Use text inputs instead of dropdowns
チェックを入れると、ドロップダウンで選択可能な各種タイプの設定をテキストで直接指定できます。
ドロップダウンで選択するか直接テキストを打つかの設定が可能ですが、好みの問題でもあります。

まとめ
Stable Diffusion Web UI(AUTOMATIC1111)について、基本機能となるtxt2img(text to image)について、設定画面と内容に関する詳しい説明を行いました。


コメント