
Power Automate Desktop(PAD)で、PDFからテキストを抽出する方法について解説します。
【事前準備】抽出対象のファイルを用意する
※すでにテキストを抽出したいPDFファイルがある場合は、この工程は不要です。
Webページなどで、PDFのページになっておりそこからテキストを抽出したい場合は、まず「PDFファイル」としてファイルをご自身の端末に保存しておく必要があります。
例えば、以下のページであれば、右上のダウンロードアイコンからpdfファイルをダウンロードしておきます。
他にも、ExcelやWordであれば、「名前を付けて保存」で拡張子を .pdf に設定して保存し、取得対象のPDFを用意しておきます。
「PDFからテキストを抽出」の使い方
まず、「PDFからテキストを抽出」アクションを追加します。
PDFからテキストを抽出
左側のアクション一覧から「PDFからテキストを抽出」を選んで、ドラッグアンドドロップで真ん中の白いエリアに配置します。
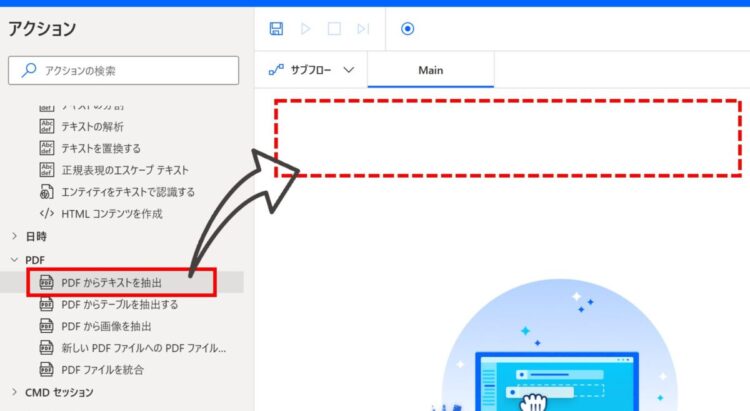
アクションを追加すると、以下のようなダイアログが表示されます。
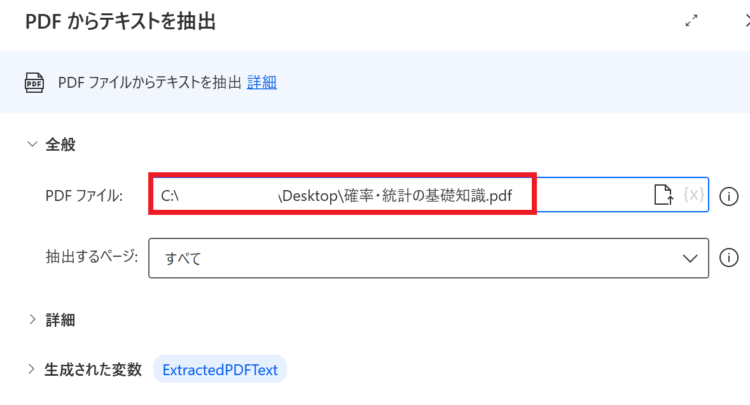
- PDFファイル:テキストを読み取りたいPDFファイルのフルパス
- 抽出するページ:すべて/ 単一/ 範囲 から選択
- パスワード:「詳細」にメニューあり。パスワード付きPDFを開く際には設定します
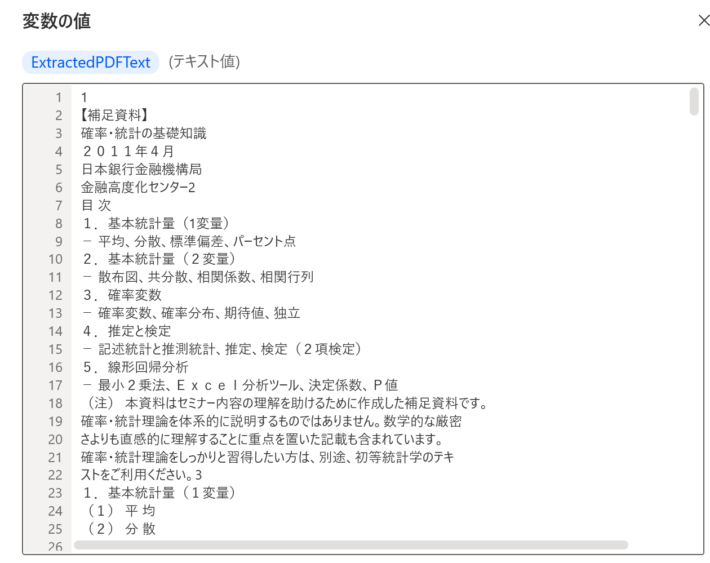
このフローを実行すると、以下のようにPDF内のテキストが抽出されます。
【応用】PDF内の表をExcelに転記する
【2024/02/29追記】
こんな面倒な方法でなくても、PADに用意されている「PDFからテーブルを抽出する」アクションを使用すると簡単にテーブル(表)の内容が取得できました。

PDF内の表をExcelに転記する方法について解説します。
例として、以下の表をExcelに転記する方法を解説します。
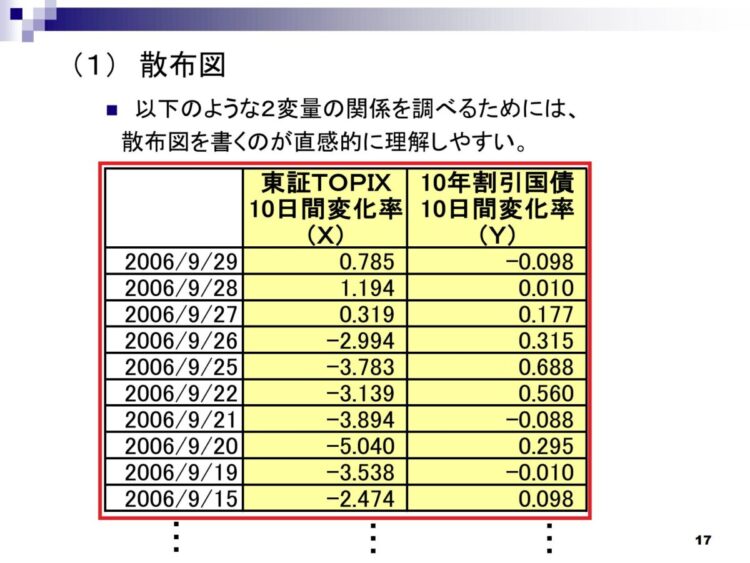
表の部分だけ取り出すために、データの開始位置と終了位置を検索し、該当する部分を取り出します。
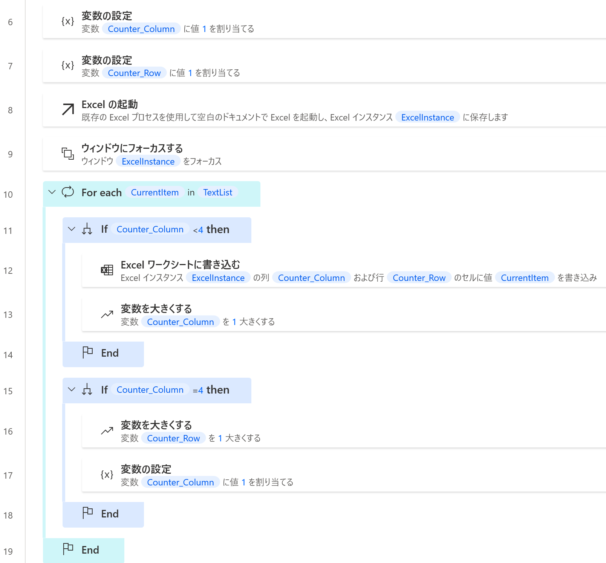
列数・行数それぞれカウンター変数を持たせて、Excelに転記します。
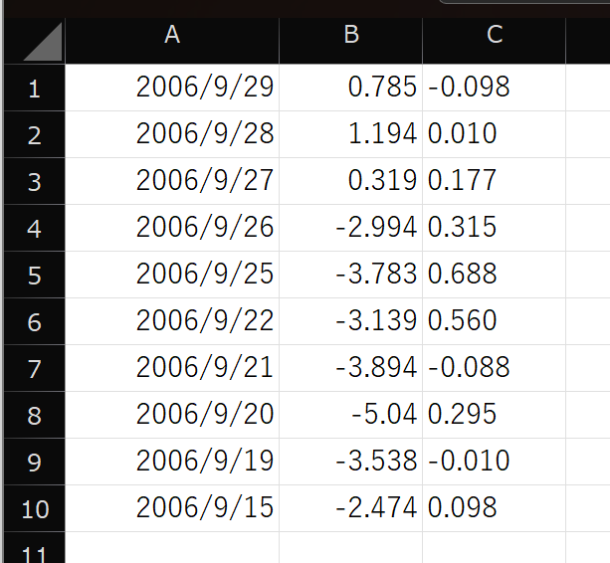
本フローを実行すると、表の内容がExcelに転記されます。
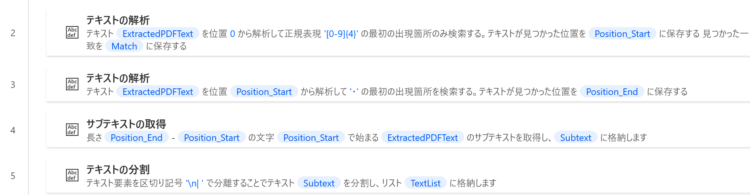
PDFから取得したテキストを解析するためのアクション
PDFから取得したテキストを解析するためには、テキスト操作のアクションを使用します。
▼文字列の取り出し

まとめ
今回は、Power Automate Desktop(PAD)で、PDFからテキストを抽出する方法について解説しました。
PDFから読み取ったテキストは、ひとかたまりのテキストとして変数に格納されるため、そこから部分的に取り出したい場合はさらにアクションを追加して加工する必要があります。また、表の取り出しは少し手間がかかるなと思いました。もっと簡単にできる方法が見つかったら共有させていただきます。
当ブログでは、Power Automate、Power Automate Desktopに関する記事を他にも投稿しています。もし、「このようなことが知りたい」「こんなフローの作り方が知りたい」等ございましたら、問い合わせやコメントからお気軽にご連絡ください。



コメント