
今回は、オープンソースのデータコレクター(ログ収集ツール)である「Fluentd」のインストール手順と、基本的な使い方を紹介します。
はじめに
オープンソースのデータコレクターであるFluentdについて、基本的な使い方をコードや画像を交えて紹介します。
「Fluentdとはなんだ?」という方や、インストール方法が知りたいという場合は、以下の記事を参考にしてください。

Fluentdの使い方
confファイル内の基本
データを集めたり、どこかに出力や転送する場合は、conf(設定)ファイルに記載します。インストールするOSにより、confファイルができる場所が決まっています。公式ドキュメントを参照してください。
conf(設定)ファイルは以下の要領に従って作成していきます。
- 入力と出力のプラグインを選択
- プラグインのパラメータを指定
基本的には、上記を組み合わせて繰り返し、Fluentdの入力と出力をユーザの意図したままに制御するように設定していきます。
ディレクティブ
fluentdは「ディレクティブ」という単位で構成されます。以下のディレクティブで構成されます。
| ディレクティブ | 概要 |
|---|---|
| sourceディレクティブ | 入力ソースを決定します。 |
| matchディレクティブ | 出力先を決定します。 |
| filterディレクティブ | イベント処理のパイプラインを決定します。 |
| systemディレクティブ | システム全体の設定を設定します。 |
| labelディレクティブ | 出力をグループ化し、内部ルーティングのためにフィルタします。 |
| workerディレクティブ | 特定のワーカーに限定します。 |
| @includeディレクティブ | 他のファイルをインクルードします。 |
@includeディレクティブ以外はhtmlのような書き方をします。
<source>
ここに処理を書く
</source>プラグイン
Fluentdにはプラグインというものがあります。
これは機能を拡張し、異なるデータソースやデータの転送先との連携を可能にするための追加モジュールです。
プラグインは、データの入力、出力、フィルタリング、バッファリングなどのさまざまな機能を提供します。プラグインを組み合わせて様々な機能を実現することができます。
また、必要な機能がないときは、自身プラグインを開発することもできます。
主に以下のようなタイプのプラグインが存在します。
| プラグイン | 概要 |
|---|---|
| Inputプラグイン | Fluentdにデータを供給するためのソースを定義します。 ログファイル、データベース、メッセージングキューなど、さまざまなデータソースからのデータをFluentdに取り込むために使用されます。 |
| Outputプラグイン | Fluentdが処理したデータを転送する先を定義します。 データベース、データウェアハウス、ストレージシステム、メッセージングシステムなど、さまざまなデータストアやサービスにデータを送信するために使用されます。 |
| Filterプラグイン | Fluentdがデータを加工、変換、フィルタリングするための機能を提供します。 データのパース、正規化、フィールドの追加・削除、データの変換などの操作を実行することができます。 |
| Parserプラグイン | Fluentdがデータを解析するためのルールやフォーマットを提供します。 データの形式や構造に基づいて、ログやイベントを解析してフィールドに分割することができます。 |
| Bufferプラグイン | Fluentdがデータを一時的に保持するためのバッファリング機能を提供します。 データの一時的な保存やバックプレッシャーの制御に使用され、データ転送の信頼性や可用性を向上させます。 |
基本的には、ディレクティブとプラグインを組み合わせて、自分の行いたい動作を作っていきます。
プラグインのインストール方法
プラグインは以下のコマンドでインストールします。
gem install プラグイン名【実践】confファイルを設定してみる
例題1
例題1として、次のことを行うためのconfファイルを作成します。
- Windowsのイベントログを取得
- 自身のコンソール(コマンドプロンプト)に取り込んだログを出力
- AWS S3にデータを転送
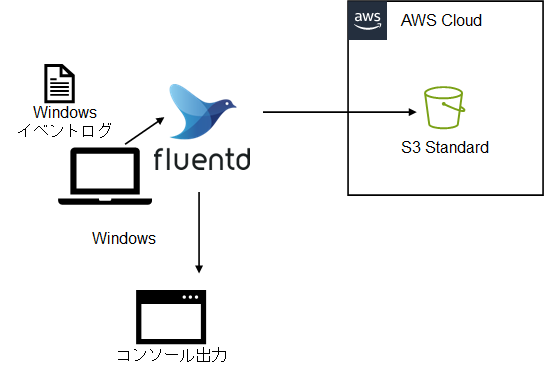
※Windowsのイベントログ取得なので、Windowsでの内容です。
プラグインインストール
必要なプラグインをインストールします。
Windowsイベントログを取得するプラグインを、以下のコマンドを入力し、インストールします。
gem install fluent-plugin-windows-eventlog他にも、以下のプラグインをインストールします。
gem install fluent-plugin-parser-winevt_xmlAWS S3にアップロードするためのプラグインを、以下のコマンドを入力し、インストールします。
gem install fluent-plugin-s3Windowsイベントログを取得する
confファイルに以下の内容を記述します。
その他オプションなどは、公式ページを参照してください。
<source>
@type windows_eventlog2
@id windows_eventlog2
read_interval 2
tag winevt.raw
render_as_xml false
rate_limit 200
read_existing_events true
<storage>
@type local
persistent true
path ./storage.json
</storage>
<subscribe>
channels ["application", "system", "setup", "security"]
</subscribe>
</source>上記の設定内容は以下のようになります。
| 項目 | 概要 |
|---|---|
| @type windows_eventlog2 | typeを「windows_eventlog2」に設定します。 |
| @id windows_eventlog2 | idを「windows_eventlog2」に設定します。 |
| read_interval 2 | イベントログを読み取る間隔を指定します。 |
| tag winevt.raw | この取得内容について、「winevt.raw」という 名称でタグを設定します。 |
| render_as_xml false | イベントログをXML形式ではなく、 生のテキスト形式で処理する指定です。 |
| rate_limit 200 | 1秒あたりに読み込まれるレコードのおおよその最大数を指します。 10の倍数で設定します。 1秒間にこの値以上のレコードが読み込まれると、読み取りを停止し、次のread_intervalまで待機します。上限なく読み込みたい場合はこの項目を書かないか、-1を設定します。 |
| <storege></storage> | Fluentdが読み取ったデータ(イベントログ)の一時的な保管場所を設定します。 |
| @type local | ストレージの種類を指定します。 今回の場合はローカルストレージになります。 |
| persistent true | データを永続的に保存するかを指定します。 |
| path ./storage.json | 保存先と名称を指定します。 |
| <subscribe></subscribe> | 購読するデータの設定を行います。 |
| channels [“application”, “system”, “setup”, “security”] | 読み込むイベントログの内容を指定します。 setupとsecurityはFluentdを管理者権限で起動する必要があります。 |
コンソールとS3にアップロード
confファイルの続きです。コンソールとS3にアップロードするための記載は以下になります。
<match winevt.raw>
@type copy
<store>
@type stdout
</store>
<store>
@type s3
aws_key_id YOUR_AWS_KEY_ID
aws_sec_key YOUR_AWS_SECRET/KEY
s3_bucket YOUR_S3_BUCKET_NAME
path YOUR_S3_PATH
<buffer>
@type file
path /var/log/td-agent/s3
timekey 3600
timekey_wait 10m
chunk_limit_size 256m
</buffer>
time_slice_format %Y%m%d%H
</store>
</match>| 項目 | 概要 |
|---|---|
| <match winevt.raw></match> | タグが「winevt.raw」に該当する場合に処理を行うということです。 前段でイベントログに対してタグをつけましたので、そのタグに対して処理を行います。 |
| @type copy | 一つのデータに対して、複数の処理を行いたいときは、上記を入れます。 今回は自身のコンソールとS3にアップロードするという2つの処理を行うので入れています。 |
| <store></store> | 処理を行いたいグループごとに囲みます。 今回は自身のコンソールとS3にアップロードするという2つの処理を行うので処理ごとに囲っています。 |
| @type stdout | コンソール出力(標準出力、コマンドプロンプトに出力)します。 |
| @type s3 | タイプを「S3」に設定します。 AWS S3で使用するkey_idとsec_key、S3のバケット名称とリージョン、保存先のパスを設定します。 ・aws_key_id YOUR_AWS_KEY_ID ・aws_sec_key YOUR_AWS_SECRET/KEY ・s3_bucket YOUR_S3_BUCKET_NAME ・s3_region ap-northeast-1 ・path YOUR_S3_PATH |
| <buffer></buffer> | ログデータを逐一送信するのではなく、バッファーとして貯めてから送信します。 |
| @type file | ファイルに出力します。 ・timekey 3600 ・timekey_wait 10m ・chunk_limit_size 256m データの貯め方を指定します。 timekey_waitで指定した時間ごとにデータを蓄積します。 timekeyで指定された時間で、それらのデータを1つにまとめます。 最後に、データの出力をchunk_limit_sizeで指定したサイズごとに分割します。 今回の設定では10分ごとにデータを一旦蓄積し、1時間経過後、256MBごとにデータファイルを作成します。 |
| time_slice_format %Y%m%d%H | アップロードするファイル名フォーマットを指定します。 |
例題2
例題2として、次のことを行うためのconfファイルを作成します。
- Windowsのイベントログを取得し、別のFluentdに転送する(PC①、PC②)
- 別途受けるPCを用意して、転送されてきたログを表示し、AWS S3にデータ転送(PC③)
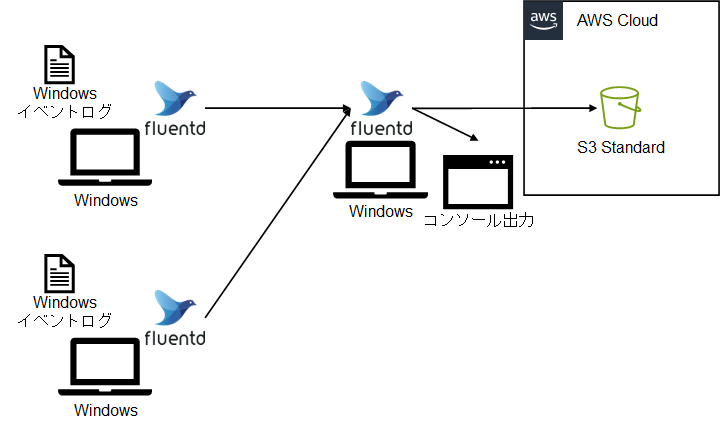
プラグインインストール
PC①とPC②に以下のコマンドを入力し、プラグインのインストールします。
gem install fluent-plugin-windows-eventlog
gem install fluent-plugin-parser-winevt_xmlPC③に以下のコマンドを入力し、プラグインをインストールします。
gem install fluent-plugin-s3PC①とPC②のfluent.confファイル記載方
Windowsイベントログの収集方法については、例題1と同様です。
<source>
@type windows_eventlog2
@id windows_eventlog2
read_interval 2
tag winevt.raw
render_as_xml false
rate_limit 200
read_existing_events true
<storage>
@type local
persistent true
path ./storage.json
</storage>
<subscribe>
channels ["application", "system", "setup", "security"]
</subscribe>
</source>以降の部分を記載します。
<match winevt.raw>
@type forward
send_timeout 60s
recover_wait 10s
hard_timeout 60s
<server>
name myserver1
host 192.168.1.1
port 24224
</server>
<secondary>
@type file
path FILE_PATH
</secondary>
</match>| 項目 | 概要 |
|---|---|
| <match winevt.raw></match> | タグが「winevt.raw」に該当する場合に処理を行います。 |
| @type forward | 転送する側はforwardのタイプを指定する必要があります。 |
| send_timeout 60s | send_timeout:イベントログ送信時のタイムアウト時間を設定します。 |
| recover_wait 10s | recover_wait:サーバ(データ送信先)が障害となった際に、 復旧するまでの待ち時間を設定します。 |
| hard_timeout 60s | hard_timeout:サーバ(データ送信先)が障害となったと 検出するまでの時間を設定します。 |
| <server></server> | サーバ(データ送信先)の情報を設定します。 |
| name myserver1 | サーバ(データ送信先)の名前を設定します。 ホスト名の場合はTLSのロギングと証明書の検証に利用されます。 |
| host 192.168.1.1 | サーバ(データ送信先)のIPアドレスまたはホスト名を設定します。 |
| port 24224 | ホスト側のポート番号を指定します。 このポートはTCPとUDP両方使用されます。 |
| <secondary></secondary> | サーバ(データ送信先)にデータを送信できない場合の挙動を設定します。 |
| @type file | ファイルとしてデータを保存します。 ちなみに、プライマリとセカンダリのタイプが異なるのは推奨されていないようなので以下のようなワーニングが出ます。 Use different plugin for secondary. Check the plugin works with primary like secondary_file primary="Fluent::Plugin::ForwardOutput" secondary="Fluent::Plugin::FileOutput" |
| path FILE_PATH | ファイル保存先のパスを設定します。 |
PC③のfluent.confファイル記載方
<source>
@type forward
port 5000
bind 0.0.0.0
</source>
<match **>
@type copy
<store>
@type stdout
</store>
<store>
@type s3
aws_key_id YOUR_AWS_KEY_ID
aws_sec_key YOUR_AWS_SECRET/KEY
s3_bucket YOUR_S3_BUCKET_NAME
path YOUR_S3_PATH
<buffer>
@type file
path /var/log/td-agent/s3
timekey 3600
timekey_wait 10m
chunk_limit_size 256m
</buffer>
time_slice_format %Y%m%d%H
</store>
</match>| 項目 | 概要 |
|---|---|
| <source></source> | 受けるデータの設定を行います。 |
| @type forward | 転送を受ける側は必ずforwardにする必要があります。 |
| port 5000 | 受けるポートを設定します。 |
| bind 0.0.0.0 | どのIPから受けるか決定します。 0.0.0.0はすべてのIPから受ける設定となります。 |
| <match **></match> | 処理するタグを決定します。 **の場合はすべてのタグに対して処理します。 |
<match></match>内の記述は例1のコンソール出力とS3格納と同じです。
Fluentdを起動する
コマンドプロンプトを起動し、以下のコマンドを入力しFluentdを起動します。イベントログの種類によっては、コマンドプロンプトを管理者で実行します。
fluentd -c fluent.confファイルパス(相対または絶対パス)コマンドプロンプトからconf/fluent.confがある場合、以下のように起動すると、Fluentdが動き出します。
fluentd -c ./conf/fluent.conf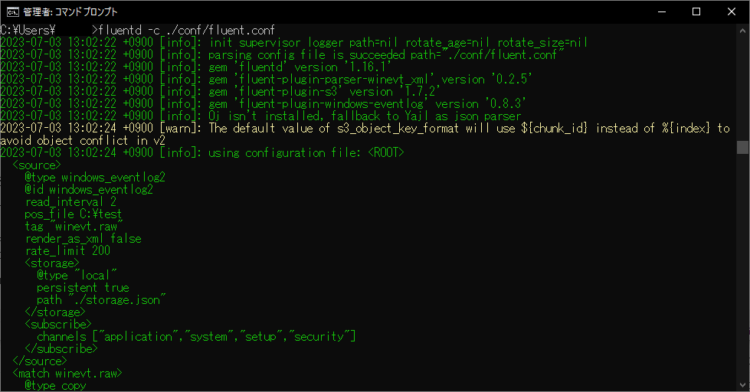
実際にコンソールに取得したデータが出力されます。
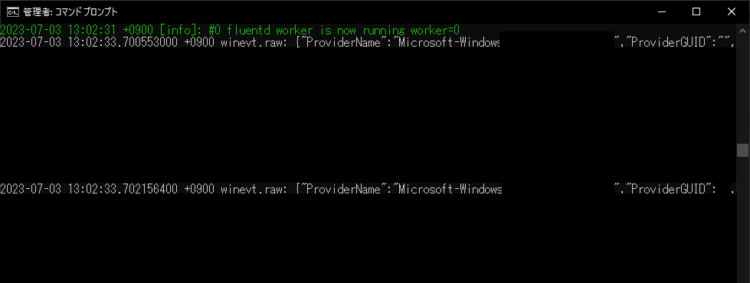
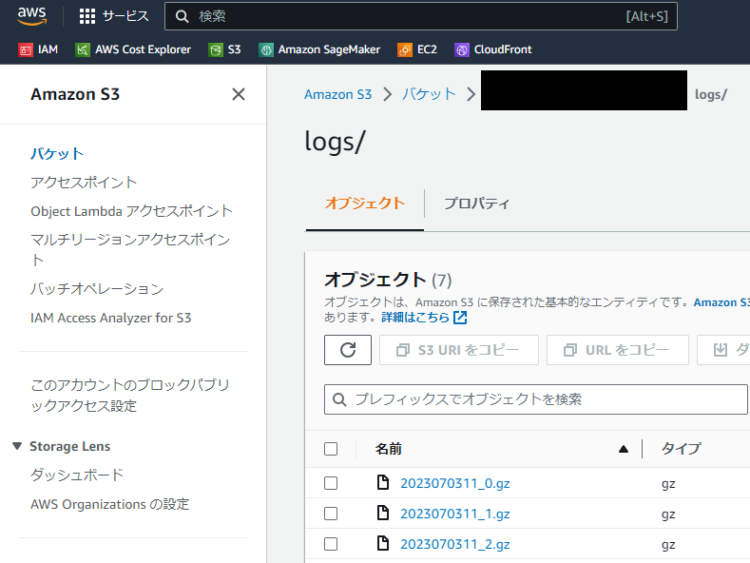
また、S3の指定したバケットにデータが保存されます。
エラーが出て処理が止まる場合
主に以下の原因が考えられます。
gemインストールモジュールが不足している
gemインストールするべきモジュールがインストールされてない場合、エラーが発生し処理が止まります。その際はモジュール名のようなものが書かれているので、それをインストールします。
実行権限とファイルアクセス権限の確認
コンソールを管理者権限で実行しないと取れないデータが存在します。
- S3周りの権限
unexpected error error_class=RuntimeError error="can't call S3 API. Please check your credentials or s3_region configuration.のようなメッセージが出るときは、S3の書き込み権限がうまく働いていません。
IAMのアクセスキーを有効化しているかなどを確認してください。
- 指定場所にファイルができない
指定が絶対パスの場合、「\」はエスケープされるので2つ必要です。
例:C:\hoge\huga→C:\hoge\huga
まとめ
Fluentdの基本的な設定方法と動作方法について紹介しました。
これから利用を検討されている方や操作に慣れていない方は、まずは本記事の例題を試してみると良いかと思います。
本記事が参考になれば幸いです。


コメント