
Power Automate Desktop(PAD)の「PDFから画像を抽出」アクションの使い方について解説します。
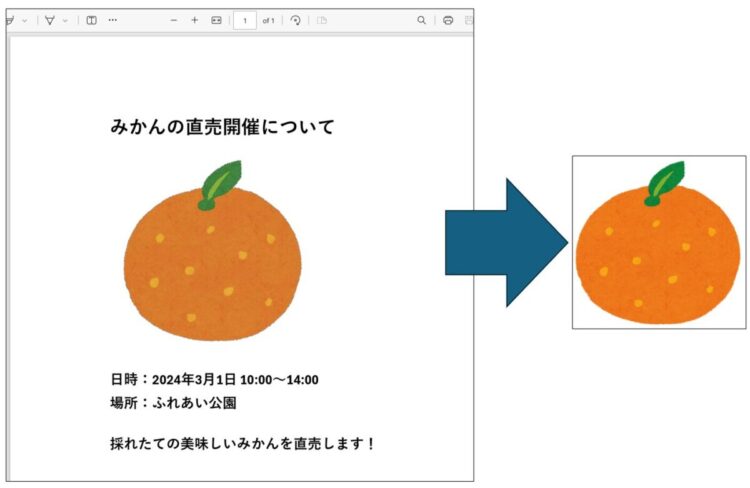
「PDFから画像を抽出」の使い方
PADの編集画面で、以下のアクションを追加します。
PDFから画像を抽出
「PDFから画像を抽出」アクションを、真ん中の白いエリアにドラッグアンドドロップで追加します。
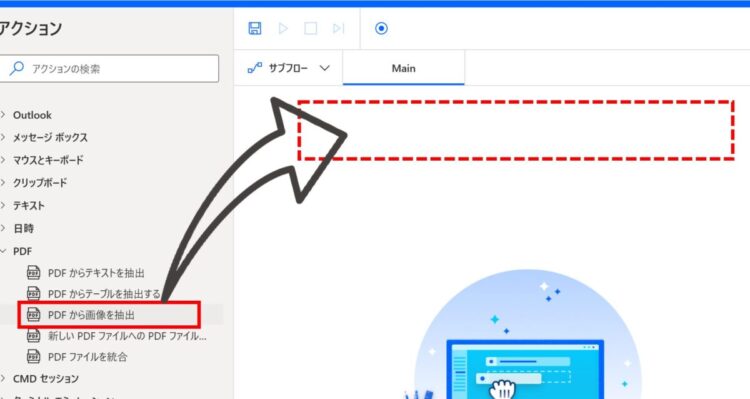
追加すると、以下のようなダイアログが表示されます。

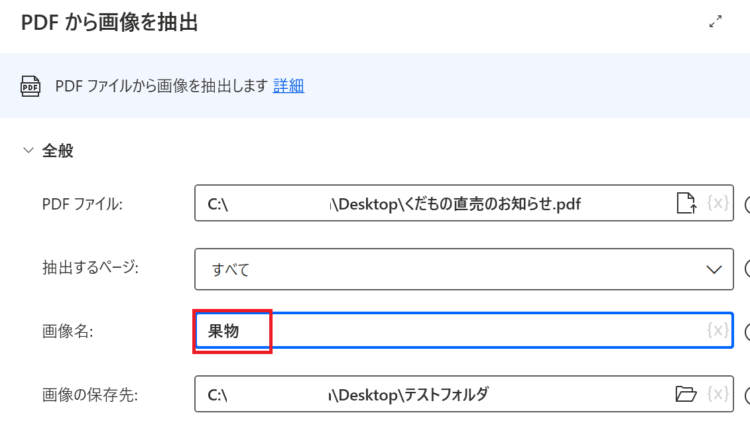
- PDFファイル:対象となるPDFファイルのフルパス
- 抽出するページ:すべて/ 単一/ 範囲 から選択
- 画像名:取得した画像の名前(拡張子は不要。PNGで保存されます)
- 画像の保存先:画像の保存先となるフォルダ
このフローを実行すると、指定したフォルダに画像が保存されていることを確認できました。
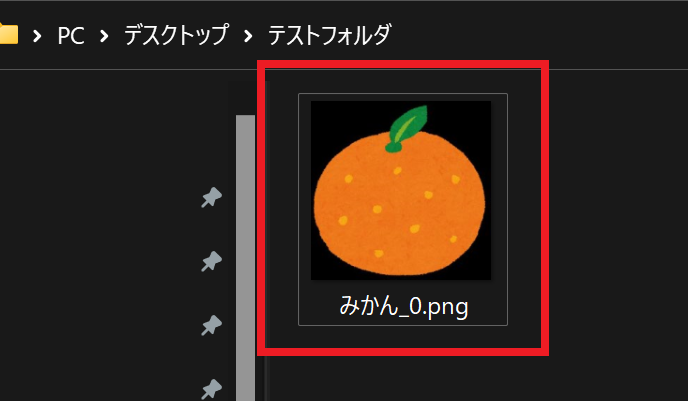
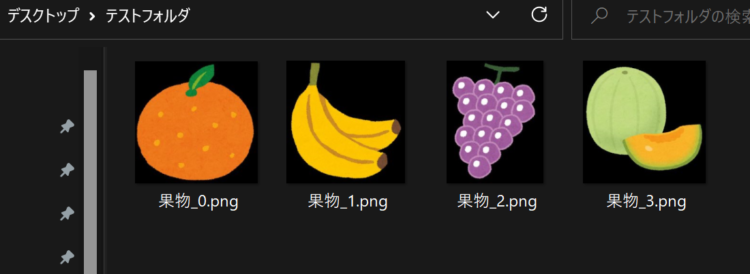
PDF内に複数の画像が含まれる場合

PDF内に複数の画像が含まれる場合、
画像名は「画像名_0.png」「画像名_1.png」「画像名_2.png」・・・のようになります。
注意:取得した画像の背景は黒になる
サンプルで解説したみかんの画像を見ても分かる通り、取得した画像に余白がある場合、黒色になります。もし、背景色を変えたい場合はペイントを使って簡単に変更することができます。
背景色の変更方法
ペイントを開き、上部メニュー「イメージ」内にある赤枠のアイコンを押します。
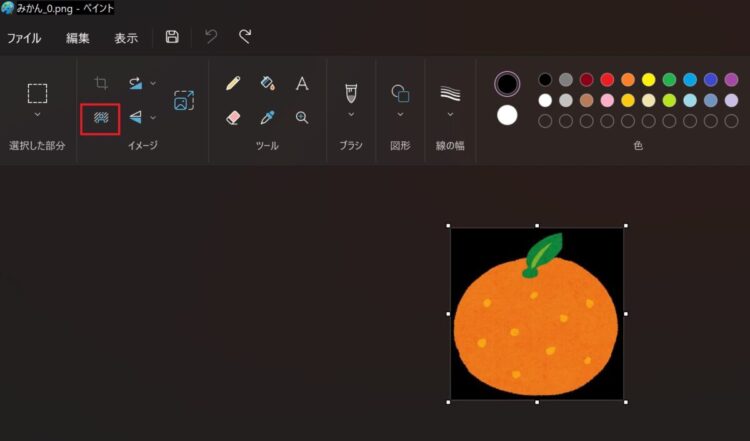
すると、背景が透過(透明)されます。
次に、画面上部の「レイヤー」を押します。
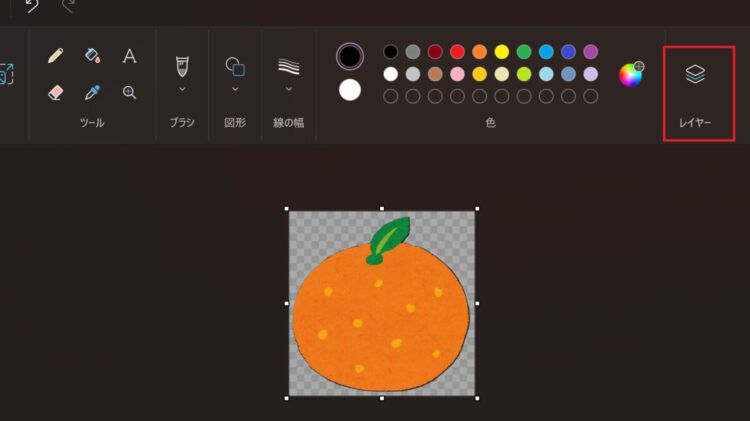
「+」マークを押してレイヤーを追加します。
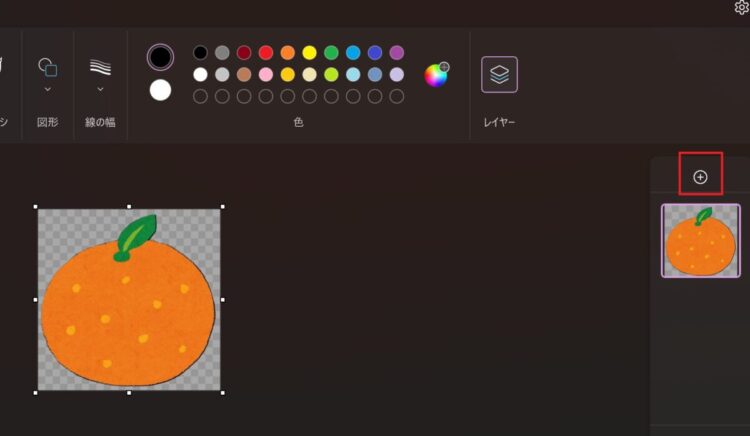
追加したレイヤーを、元の画像よりも下に移動させます。そして、追加したレイヤーを選択状態にします。

画面上部メニュー「ツール」から「塗りつぶし」を選択して、指定した色で塗りつぶします。
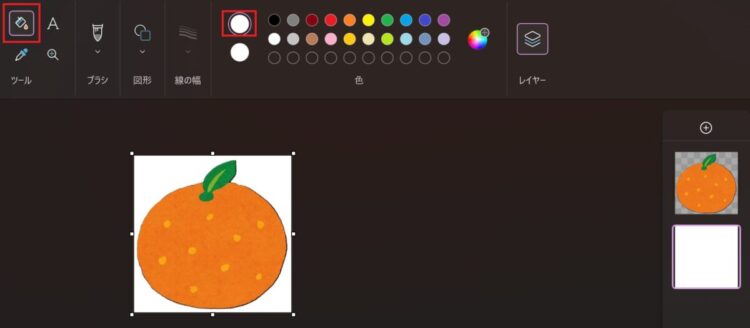
「フラット化した画像として保存しますか?」と聞かれるので、「OK」を押します。これで、レイヤーが統合されてひとつの画像として保存されます。
↓完成した画像(ちょっと枠の黒い部分が残ってしまってます。もっと綺麗に加工したい場合は別のアプリ等を活用してみてください)

まとめ
今回は、Power Automate Desktop(PAD)の「PDFから画像を抽出」アクションの使い方について解説しました。
当ブログでは、Power Automate、Power Automate Desktopに関する記事を他にも投稿しています。もし、「このようなことが知りたい」「こんなフローの作り方が知りたい」等ございましたら、問い合わせやコメントからお気軽にご連絡ください。



コメント